
Содержание
Обнаружение объектов - это задача компьютерного зрения, связанная с идентификацией и определением местоположения объектов на изображениях или видео. Она является важной частью многих приложений, таких как самоуправляемые автомобили, робототехника и видеонаблюдение.
За прошедшие годы было разработано множество методов и алгоритмов, позволяющих находить объекты на изображениях и определять их положение. Отличное качество при выполнении этих задач достигается при использовании сверточных нейронных сетей.
Одной из самых популярных нейронных сетей для решения этой задачи является YOLO, созданная в 2015 году Джозефом Редмоном, Сантошем Диввалой, Россом Гиршиком и Али Фархади в их известной научной работе “You Only Look Once: Unified, Real-Time Object Detection”.
С тех пор появилось довольно много версий YOLO. Последние версии могут делать даже больше, чем обнаружение объектов. Самой новой версией является YOLOv8, которую мы будем использовать в этом учебном пособии.
Здесь я покажу основные возможности этой сети для обнаружения объектов. Сначала мы используем предварительно обученную модель для обнаружения таких распространенных классов объектов, как кошки и собаки. Затем я покажу, как обучить собственную модель для обнаружения конкретных типов объектов, которые вы выберете, и как подготовить данные для этого процесса. Наконец, мы создадим веб-приложение для обнаружения объектов на изображениях прямо в веб-браузере с использованием собственной обученной модели.
Для того чтобы следовать этому руководству, вы должны быть знакомы с языком Python и иметь базовое представление о машинном обучении, нейронных сетях и их применении для обнаружения объектов. Для ознакомления со всей необходимой теорией машинного обучения можно посмотреть этот краткий видеокурс.
После того как вы освежили теорию, давайте приступим к практике!
Задачи, которые может решать YOLOv8
С помощью сети YOLOv8 можно решать задачи классификации, обнаружения объектов и сегментации изображений. Все эти методы по-разному обнаруживают объекты на изображениях или видео, как показано на рисунке ниже:

Общие проблемы компьютерного зрения - классификация, обнаружение и сегментация
Нейронная сеть, созданная и обученная для классификации изображений, определяет класс объекта на изображении и выдает его название, а также вероятность такого прогноза.
Например, на левом изображении было получено, что это “кошка” и что уровень доверия к этому предсказанию составляет 92% (0,92).
Нейронная сеть обнаружения объектов, помимо типа объекта и вероятности, возвращает координаты объекта на изображении: x, y, ширину и высоту, как показано на втором изображении. Нейронные сети обнаружения объектов могут также определять несколько объектов на изображении и их ограничительные рамки.
Наконец, в дополнение к типам объектов и ограничительным рамкам нейронная сеть, обученная для сегментации изображений, определяет формы объектов, как показано на правом изображении.
Для этих задач разработано множество различных архитектур нейронных сетей, и для каждой из них раньше приходилось использовать отдельную сеть. К счастью, после создания YOLO ситуация изменилась. Теперь для решения всех этих задач можно использовать единую платформу.
В этой статье мы рассмотрим обнаружение объектов с помощью YOLOv8. Я расскажу вам о том, как создать веб-приложение, которое будет обнаруживать на изображениях светофоры и дорожные знаки. В последующих статьях я расскажу о других функциях, включая сегментацию изображений.
В следующих разделах мы рассмотрим все шаги, необходимые для создания детектора объектов. К концу этого урока у вас будет готовое веб-приложение с поддержкой искусственного интеллекта.
Как начать работу с YOLOv8
С технической точки зрения YOLOv8 - это группа моделей конволюционных нейронных сетей, созданных и обученных с помощью фреймворка PyTorch.
Кроме того, пакет YOLOv8 предоставляет единый Python API для работы со всеми моделями с помощью одних и тех же методов. Поэтому для его использования необходима среда для выполнения Python-кода. Я настоятельно рекомендую использовать Jupyter Notebook.
Убедившись, что на компьютере установлены Python и Jupyter, запустите блокнот и установите в него пакет YOLOv8, выполнив следующую команду:
!pip install ultralytics
В пакете ultralytics имеется класс YOLO, используемый для создания нейросетевых моделей.
Чтобы получить к нему доступ, импортируйте его в свой Python-код:
from ultralytics import YOLO
Теперь все готово для создания нейросетевой модели:
model = YOLO("yolov8m.pt")
Как я уже упоминал, YOLOv8 представляет собой группу нейросетевых моделей. Эти модели были созданы и обучены с помощью PyTorch и экспортированы в файлы с расширением .pt.
Существует три типа моделей и по 5 моделей разного размера для каждого типа:
| Classification | Detection | Segmentation | Kind |
| yolov8n-cls.pt | yolov8n.pt | yolov8n-seg.pt | Nano |
| yolov8s-cls.pt | yolov8s.pt | yolov8s-seg.pt | Small |
| yolov8m-cls.pt | yolov8m.pt | yolov8m-seg.pt | Medium |
| yolov8l-cls.pt | yolov8l.pt | yolov8l-seg.pt | Large |
| yolov8x-cls.pt | yolov8x.pt | yolov8x-seg.pt | Huge |
Чем больше модель, тем выше качество предсказания, но тем медленнее она будет работать.
В данном руководстве я буду рассматривать обнаружение объектов, поэтому в предыдущем фрагменте кода я выбрал модель “yolov8m.pt”, которая является моделью среднего размера для обнаружения объектов.
При первом запуске этого кода он загрузит файл yolov8m.pt с сервера Ultralytics в текущую папку. Затем будет построен объект модели. Теперь можно обучать эту модель, обнаруживать объекты и экспортировать ее для использования в производстве. Для всех этих задач существуют удобные методы:
- train({путь к файлу дескриптора набора данных}) - используется для обучения модели на наборе данных изображений.
- predict({image}) - используется для предсказания для заданного изображения, например, для определения ограничивающих рамок всех объектов, которые модель может найти на изображении.
- export({формат}) - используется для экспорта модели из стандартного формата PyTorch в заданный формат.
Все модели YOLOv8 для обнаружения объектов уже предварительно обучены на наборе данных COCO, который представляет собой огромную коллекцию изображений 80 различных типов. Поэтому, если у вас нет специфических потребностей, то вы можете просто запустить ее как есть, без дополнительного обучения.
Например, вы можете загрузить это изображение как “cat_dog.jpg”:

Пример изображения с кошкой и собакой
и запустить предсказание для обнаружения всех объектов на нем:
results = model.predict("cat_dog.jpg")
Метод predict принимает множество различных типов входных данных, включая путь к одному изображению, массив путей к изображениям, объект Image известной библиотеки PIL Python и другие.
После прогона входных данных через модель он возвращает массив результатов для каждого входного изображения. Поскольку мы предоставили только одно изображение, возвращается массив с одним элементом, который можно извлечь следующим образом:
result = results[0]
Результат содержит обнаруженные объекты и удобные свойства для работы с ними. Наиболее важным из них является массив boxes, содержащий информацию об обнаруженных ограничительных границах на изображении. Количество обнаруженных объектов можно определить, выполнив функцию len:
len(result.boxes)
При запуске я получил значение “2”, что означает, что обнаружено две коробки: одна для собаки, другая для кошки.
Далее можно проанализировать каждый ящик либо в цикле, либо вручную. Возьмем первый:
box = result.boxes[0]
Объект box содержит свойства ограничивающей рамки, в том числе:
- xyxy - координаты рамки в виде массива [x1,y1,x2,y2].
- cls - идентификатор типа объекта
- conf - уровень доверия модели к данному объекту. Если он очень низкий, например < 0.5, то коробку можно просто игнорировать.
Выведем информацию об обнаруженном ящике:
print("Object type:", box.cls)
print("Coordinates:", box.xyxy)
print("Probability:", box.conf)
Для первой коробки вы получите следующую информацию:
Object type: tensor([16.])
Coordinates: tensor([[261.1901, 94.3429, 460.5649, 312.9910]])
Probability: tensor([0.9528])
Как я уже объяснял выше, YOLOv8 содержит модели PyTorch. Выходы моделей PyTorch закодированы в виде массива объектов PyTorch Tensor, поэтому необходимо извлечь первый элемент из каждого из этих массивов:
print("Object type:",box.cls[0])
print("Coordinates:",box.xyxy[0])
print("Probability:",box.conf[0])
Object type: tensor(16.)
Coordinates: tensor([261.1901, 94.3429, 460.5649, 312.9910])
Probability: tensor(0.9528)
Теперь вы видите данные в виде объектов Tensor. Для распаковки фактических значений из Tensor необходимо использовать метод .tolist() для тензоров с массивом внутри, а также метод .item() для тензоров со скалярными значениями.
Извлечем данные в соответствующие переменные:
cords = box.xyxy[0].tolist()
class_id = box.cls[0].item()
conf = box.conf[0].item()
print("Object type:", class_id)
print("Coordinates:", cords)
print("Probability:", conf)
Object type: 16.0
Coordinates: [261.1900634765625, 94.3428955078125, 460.5649108886719, 312.9909973144531]
Probability: 0.9528293609619141
Теперь вы видите фактические данные. Координаты можно округлять, и вероятность также можно округлять до двух цифр после точки.
Тип объекта здесь равен 16. Что это означает? Давайте поговорим об этом подробнее.
Все объекты, которые может обнаружить нейронная сеть, имеют числовые идентификаторы. В случае предварительно обученной модели YOLOv8 существует 80 типов объектов с идентификаторами от 0 до 79. Классы объектов COCO хорошо известны, и их можно легко найти в Интернете. Кроме того, объект результата YOLOv8 содержит удобное свойство names для получения этих классов:
print(result.names)
{0: 'person',
1: 'bicycle',
2: 'car',
3: 'motorcycle',
4: 'airplane',
5: 'bus',
6: 'train',
7: 'truck',
8: 'boat',
9: 'traffic light',
10: 'fire hydrant',
11: 'stop sign',
12: 'parking meter',
13: 'bench',
14: 'bird',
15: 'cat',
16: 'dog',
17: 'horse',
18: 'sheep',
19: 'cow',
20: 'elephant',
21: 'bear',
22: 'zebra',
23: 'giraffe',
24: 'backpack',
25: 'umbrella',
26: 'handbag',
27: 'tie',
28: 'suitcase',
29: 'frisbee',
30: 'skis',
31: 'snowboard',
32: 'sports ball',
33: 'kite',
34: 'baseball bat',
35: 'baseball glove',
36: 'skateboard',
37: 'surfboard',
38: 'tennis racket',
39: 'bottle',
40: 'wine glass',
41: 'cup',
42: 'fork',
43: 'knife',
44: 'spoon',
45: 'bowl',
46: 'banana',
47: 'apple',
48: 'sandwich',
49: 'orange',
50: 'broccoli',
51: 'carrot',
52: 'hot dog',
53: 'pizza',
54: 'donut',
55: 'cake',
56: 'chair',
57: 'couch',
58: 'potted plant',
59: 'bed',
60: 'dining table',
61: 'toilet',
62: 'tv',
63: 'laptop',
64: 'mouse',
65: 'remote',
66: 'keyboard',
67: 'cell phone',
68: 'microwave',
69: 'oven',
70: 'toaster',
71: 'sink',
72: 'refrigerator',
73: 'book',
74: 'clock',
75: 'vase',
76: 'scissors',
77: 'teddy bear',
78: 'hair drier',
79: 'toothbrush'}
В этом словаре есть все, что может обнаружить данная модель. Теперь вы можете обнаружить, что 16 - это “собака”, так что это ограничительное поле является ограничительным полем для обнаруженной DOG.
Давайте изменим вывод, чтобы показать результаты более репрезентативно:
cords = box.xyxy[0].tolist()
cords = [round(x) for x in cords]
class_id = result.names[box.cls[0].item()]
conf = round(box.conf[0].item(), 2)
print("Object type:", class_id)
print("Coordinates:", cords)
print("Probability:", conf)
В этом коде я округлил все координаты, используя списочное понимание Python. Затем я получил имя класса обнаруженного объекта по ID, используя словарь result.names. Вероятность также была округлена. Вы должны получить следующий результат:
Object type: dog
Coordinates: [261, 94, 461, 313]
Probability: 0.95
Эти данные отлично подходят для отображения в пользовательском интерфейсе. Теперь напишем код для получения этой информации для всех обнаруженных ящиков в цикле:
for box in result.boxes:
class_id = result.names[box.cls[0].item()]
cords = box.xyxy[0].tolist()
cords = [round(x) for x in cords]
conf = round(box.conf[0].item(), 2)
print("Object type:", class_id)
print("Coordinates:", cords)
print("Probability:", conf)
print("---")
Этот код выполнит аналогичные действия для каждого ящика и выдаст следующее:
Object type: dog
Coordinates: [261, 94, 461, 313]
Probability: 0.95
---
Object type: cat
Coordinates: [140, 170, 256, 316]
Probability: 0.92
---
```
Таким образом, можно запустить обнаружение объектов на других изображениях и увидеть все, что может обнаружить на них модель, обученная COCO.
В этом видеоролике показана вся сессия кодирования этого раздела в Jupyter Notebook, если, конечно, он у вас установлен.
https://www.youtube.com/watch?v=8Q87QYlonRU
Для начала можно использовать модели, предварительно обученные на известных объектах. Но на практике может потребоваться решение для обнаружения конкретных объектов для решения конкретной бизнес-задачи.
Например, может потребоваться обнаружить конкретные товары на полках супермаркетов или обнаружить опухоли мозга на рентгеновских снимках. Вполне вероятно, что такая информация отсутствует в открытых наборах данных, а бесплатных моделей, которые знают обо всем, не существует.
Поэтому необходимо обучить собственную модель обнаружению объектов такого типа. Для этого необходимо создать базу данных аннотированных изображений по вашей проблеме и обучить модель на этих изображениях.
## Как подготовить данные для обучения модели YOLOv8
Для обучения модели необходимо подготовить аннотированные изображения и разделить их на обучающий и проверочный наборы данных.
Тренировочный набор будет использоваться для обучения модели, а проверочный - для проверки результатов исследования и измерения качества обученной модели. В обучающий набор можно поместить 80% изображений, а в проверочный - 20%.
Вот шаги, которые необходимо выполнить для создания каждого из наборов данных:
- Определите и закодируйте классы объектов, которые вы хотите научить свою модель обнаруживать. Например, если вы хотите обнаруживать только кошек и собак, то можно указать, что "0" - это кошка, а "1" - собака.
- Создайте папку для набора данных и две подпапки в ней: "images" и "labels".
- Добавьте изображения в подпапку "images". Чем больше изображений вы соберете, тем лучше для обучения.
- Для каждого изображения создайте текстовый файл с аннотацией в подпапке "labels". Текстовые файлы аннотаций должны иметь те же имена, что и файлы изображений, и расширение ".txt". В файлы аннотаций необходимо добавить записи о каждом объекте, существующем на соответствующем изображении, в следующем формате:
{object_class_id} {x_center} {y_center} {width} {height}

Параметры ограничивающей рамки
Это самая трудоемкая ручная работа в процессе машинного обучения: измерить ограничительные рамки для всех объектов и добавить их в файлы аннотаций.
При этом необходимо нормализовать координаты, чтобы они укладывались в диапазон от 0 до 1. Для их расчета необходимо использовать следующие формулы:
- x_center = (box_x_left+box_x_width/2)/image_width
- y_center = (box_y_top+box_height/2)/image_height
- width = box_width/image_width
- height = box_height/image_height
Например, если вы хотите добавить в набор данных изображение "cat_dog.jpg", которое мы использовали ранее, необходимо скопировать его в папку "images", а затем измерить и собрать следующие данные об этом изображении и его ограничительных границах:
Изображение:
ширина_изображения = 612
image_height = 415
Объекты:
<table>
<tbody>
<tr>
<td><strong>Dog</strong></td>
<td><strong>Cat</strong></td>
</tr>
<tr>
<td>
box_x_left=261
box_x_top=94
box_width=200
box_height=219
</td>
<td>
box_x_left=140
box_x_top=170
box_width=116
box_height=146
</td>
</tr>
</tbody>
</table>
Затем создайте файл "cat_dog.txt" в папке "labels" и, используя приведенные выше формулы, рассчитайте координаты:
Собака (id класса=1):
x_center = (261+200/2)/612 = 0.589869281
y_center = (94+219/2)/415 = 0.490361446
ширина = 200/612 = 0.326797386
высота = 219/415 = 0.527710843
Кошка (id класса=0)
x_center = (140+116/2)/612 = 0.323529412
y_center = (170+146/2)/415 = 0.585542169
ширина = 116/612 = 0.189542484
высота = 146/415 = 0.351807229
и добавьте в файл следующие строки:
1 0.589869281 0.490361446 0.326797386 0.527710843 0 0.323529412 0.585542169 0.189542484 0.351807229
Первая строка содержит ограничительную рамку для собаки (class id=1). Вторая строка содержит ограничительную рамку для кошки (class id=0). Разумеется, на изображении может быть одновременно много собак и много кошек, и для всех них можно добавить ограничительные рамки.
После добавления и аннотирования всех изображений набор данных готов. Необходимо создать два набора данных и поместить их в разные папки. Окончательная структура папок может выглядеть следующим образом:
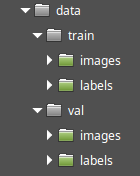
Структура набора данных
Как видно, обучающий набор данных находится в папке "train", а проверочный - в папке "val".
Наконец, необходимо создать YAML-файл дескриптора набора данных, указывающий на созданные наборы данных и описывающий классы объектов в них. Вот пример такого файла для созданных выше данных:
train: ../train/images val: ../val/images
nc: 2 names: [‘cat’,‘dog’]
В первых двух строках необходимо указать пути к изображениям обучающего и проверочного наборов данных. Пути могут быть как относительными к текущей папке, так и абсолютными.
Затем в строке nc указывается количество классов, существующих в этих наборах данных, а names представляет собой массив имен классов, расположенных в правильном порядке.
Индексы этих элементов - это числа, которые вы использовали при аннотировании изображений, и эти индексы будут возвращены моделью при обнаружении объектов с помощью метода predict. Так, если для кошки использовалось число "0", то оно должно быть первым элементом в массиве имен.
Этот YAML-файл необходимо передать в метод train модели, чтобы запустить процесс обучения.
Для облегчения процесса аннотирования изображений существует множество программ, с помощью которых можно визуально аннотировать изображения для машинного обучения. Список таких программ можно найти в поисковой системе по запросу "software to annotate images for machine learning".
Существует также множество онлайн-инструментов, которые могут выполнять всю эту работу, например Roboflow Annotate. С помощью этого сервиса достаточно загрузить изображения, нарисовать на них ограничительные рамки и задать классы для каждой ограничительной рамки. Затем инструмент автоматически создаст файлы аннотаций, разделит данные на обучающие и проверочные, а также создаст YAML-файл дескрипторов. Затем можно экспортировать и загрузить аннотированные данные в виде ZIP-файла.
В приведенном ниже видеоролике я показываю, как использовать Roboflow для создания микронабора данных "кошки и собаки".
https://www.youtube.com/watch?v=sLZRfzaRBwg
Для решения реальных задач эта база данных должна быть гораздо больше. Чтобы обучить отличную модель, необходимо иметь сотни или тысячи аннотированных изображений.
Кроме того, при подготовке базы изображений постарайтесь сделать ее сбалансированной. В ней должно быть равное количество объектов каждого класса, то есть в данном примере равное количество собак и кошек. В противном случае обученная на ней модель может предсказать один класс лучше, чем другой.
После того как данные будут готовы, скопируйте их в папку с кодом на Python, который вы будете использовать для обучения, и вернитесь в Jupyter Notebook, чтобы начать процесс обучения.
## Как обучить модель YOLOv8
После того как данные готовы, необходимо пропустить их через модель. Чтобы сделать ее более интересной, мы не будем использовать этот небольшой набор данных "кошки и собаки". Для обучения мы будем использовать другой пользовательский набор данных, содержащий светофоры и дорожные знаки. Это бесплатный набор данных, который я получил из Roboflow Universe. Нажмите "Download Dataset" и выберите формат "YOLOv8".
Если на момент прочтения этой статьи она недоступна на Roboflow, то вы можете получить ее с моего Google Drive. С помощью этого набора данных можно научить YOLOv8 обнаруживать различные объекты на дорогах, как показано на следующем скриншоте.

Демонстрация обнаружения светофоров
Вы можете открыть загруженный zip-файл и убедиться, что он уже аннотирован и структурирован по описанным выше правилам. В архиве также можно найти файл дескриптора набора данных data.yaml.
Если вы скачали архив с Roboflow, то в нем будет содержаться дополнительный набор данных "test", который не используется в процессе обучения. Изображения из него можно использовать для дополнительного тестирования самостоятельно после обучения.
Распакуйте архив в папку с вашим Python-кодом и выполните метод train для запуска цикла обучения:
```python
model.train(data="data.yaml", epochs=30)
Данные - единственная обязательная опция. В нее необходимо передать файл дескриптора YAML. Опция epochs задает количество циклов обучения (по умолчанию 100). Существуют и другие опции, которые могут повлиять на процесс и качество обучаемой модели.
Каждый цикл обучения состоит из двух фаз: фазы обучения и фазы проверки.
На этапе обучения метод train выполняет следующие действия:
- Извлекает из обучающего набора данных случайную выборку изображений (количество изображений в выборке может быть задано с помощью опции batch).
- Пропускает эти изображения через модель и получает в результате граничные поля всех обнаруженных объектов и их классы.
- Передает результат в функцию потерь, которая используется для сравнения полученного результата с корректным результатом из аннотационных файлов для этих изображений. Функция потерь вычисляет величину ошибки.
- Результат функции потерь передается оптимизатору для корректировки весов модели в зависимости от величины ошибки в нужном направлении. Это позволяет уменьшить ошибки в следующем цикле. По умолчанию используется оптимизатор SGD (Stochastic Gradient Descent), но вы можете попробовать другие, например Adam, чтобы увидеть разницу.
На этапе проверки train выполняет следующие действия:
- Извлекает изображения из набора данных для проверки.
- Пропускает их через модель и получает найденные ограничительные рамки для этих изображений.
- Сравнивает полученный результат с истинными значениями для этих изображений из текстовых файлов аннотаций.
- Вычисляется точность модели на основе разницы между фактическими и ожидаемыми результатами.
Ход и результаты каждого этапа для каждой эпохи отображаются на экране. Таким образом, вы можете видеть, как модель обучается и совершенствуется от эпохи к эпохе.
При выполнении кода обучения в цикле обучения вы увидите вывод, аналогичный приведенному ниже:

Для каждой эпохи выводится сводка по фазам обучения и проверки: строки 1 и 2 показывают результаты фазы обучения, а строки 3 и 4 - результаты фазы проверки для каждой эпохи.
Этап обучения включает в себя расчет величины ошибки в функции потерь, поэтому наиболее ценными метриками здесь являются box_loss и cls_loss.
- box_loss показывает величину ошибки при определении ограничивающих рамок.
- cls_loss показывает количество ошибок в обнаруженных классах объектов.
Почему потери разделены на разные метрики? Потому что модель может правильно определить координаты ограничительной рамки вокруг объекта, но неправильно определить класс объекта в этой рамке. Например, в моей практике она определила собаку как лошадь, но размеры объекта были определены правильно.
Если модель действительно чему-то учится на данных, то вы должны видеть, что эти значения уменьшаются от эпохи к эпохе. На предыдущем снимке экрана box_loss уменьшился: 0.7751, 0.7473, 0.742, и cls_loss тоже уменьшился: 0.702, 0.6422, 0.6211.
На этапе валидации вычисляется качество модели после обучения на изображениях из валидационного набора данных.
Наиболее ценной метрикой качества является mAP50-95 - средняя точность (Mean Average Precision). Если модель обучается и совершенствуется, то точность должна расти от эпохи к эпохе. На предыдущем скриншоте видно, что она медленно растет: 0,788, 0,788, 0,791.
Если после последней эпохи не удалось добиться приемлемой точности, можно увеличить количество эпох и запустить обучение снова. Также можно настроить другие параметры, такие как batch, lr0, lrf, или изменить используемый оптимизатор. Здесь нет четких правил, но есть много рекомендаций.
Тема настройки параметров процесса обучения выходит за рамки статьи. Думаю, что об этом можно написать книгу, и многие из них уже существуют. Их легко можно найти в Интернете. Но если говорить кратко, то в большинстве из них говорится о том, что нужно экспериментировать, пробовать все возможные варианты и сравнивать результаты.
Помимо метрик, которые показываются в процессе обучения, программа пишет много статистики на диск. При начале обучения в текущей папке создается подпапка runs/detect/train, в которую после каждой эпохи записываются различные лог-файлы.
Кроме того, после каждой эпохи происходит экспорт обученной модели в файл /runs/detect/train/weights/last.pt, а модели с наибольшей точностью - в файл /runs/detect/train/weights/best.pt. Таким образом, после завершения обучения можно получить файл best.pt для использования в производстве.
Более подробно о том, как происходит процесс обучения, можно узнать из этого видеоролика. Я использовал Google Colab - облачную версию Jupyter Notebook, чтобы получить доступ к оборудованию с более мощными GPU для ускорения процесса обучения.
На видео показано, как обучить модель на 5 эпохах и загрузить итоговую модель best.pt. В реальных задачах требуется гораздо больше эпох, и будьте готовы ждать окончания обучения несколько часов, а может быть, и дней.
После завершения работы настало время запустить обученную модель в производство. В следующем разделе мы создадим веб-сервис для обнаружения объектов на изображениях в режиме онлайн в веб-браузере.
Как создать веб-сервис для обнаружения объектов
На этом мы закончили эксперименты с моделью в Jupyter Notebook. Следующую порцию кода необходимо написать в виде отдельного проекта, используя любую Python IDE, например VS Code или PyCharm.
Веб-сервис, который мы собираемся создать, будет иметь веб-страницу с полем ввода файла и элементом HTML5 canvas.
Когда пользователь выбирает файл изображения с помощью поля ввода, интерфейс будет отправлять его на бэкенд. Затем бэкенд пропустит изображение через созданную и обученную нами модель и вернет на веб-страницу массив найденных ограничительных рамок.
Получив его, фронтенд отрисует изображение на элементе canvas, а поверх него - обнаруженные ограничительные рамки.
Сервис будет выглядеть и работать так, как показано на этом видео:
После завершения работы настало время запустить обученную модель в производство. В следующем разделе мы создадим веб-сервис для обнаружения объектов на изображениях в режиме онлайн в веб-браузере.
Как создать веб-сервис для обнаружения объектов
На этом мы закончили эксперименты с моделью в Jupyter Notebook. Следующую порцию кода необходимо написать в виде отдельного проекта, используя любую Python IDE, например VS Code или PyCharm.
Веб-сервис, который мы собираемся создать, будет иметь веб-страницу с полем ввода файла и элементом HTML5 canvas.
Когда пользователь выбирает файл изображения с помощью поля ввода, интерфейс будет отправлять его на бэкенд. Затем бэкенд пропустит изображение через созданную и обученную нами модель и вернет на веб-страницу массив найденных ограничительных рамок.
Получив его, фронтенд отрисует изображение на элементе canvas, а поверх него - обнаруженные ограничительные рамки.
Сервис будет выглядеть и работать так, как показано на этом видео:
В видеоролике я использовал модель, обученную на 30 эпохах, и она все еще не обнаруживает некоторые светофоры. Для получения лучших результатов можно попробовать обучить ее еще больше. Но отличный способ улучшить качество модели машинного обучения - это добавлять все больше и больше данных.
Поэтому в качестве дополнительного упражнения можно импортировать папку с набором данных в Roboflow, добавить в нее новые изображения и аннотировать их, а затем использовать обновленные данные для продолжения обучения модели.
Как создать фронтенд
Для начала создайте папку для нового проекта Python и в ней файл index.html для веб-страницы фронтенда. Вот содержимое этого файла:
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>YOLOv8 Object Detection</title>
<style>
canvas {
display: block;
border: 1px solid black;
margin-top: 10px;
}
</style>
</head>
<body>
<input id="uploadInput" type="file" />
<canvas></canvas>
<script>
/**
* "Upload" button onClick handler: uploads selected
* image file to backend, receives an array of
* detected objects and draws them on top of image
*/
const input = document.getElementById('uploadInput');
input.addEventListener('change', async (event) => {
const file = event.target.files[0];
const data = new FormData();
data.append('image_file', file, 'image_file');
const response = await fetch('/detect', {
method: 'post',
body: data,
});
const boxes = await response.json();
draw_image_and_boxes(file, boxes);
});
/**
* Function draws the image from provided file
* and bounding boxes of detected objects on
* top of the image
* @param file Uploaded file object
* @param boxes Array of bounding boxes in format
[[x1,y1,x2,y2,object_type,probability],...]
*/
function draw_image_and_boxes(file, boxes) {
const img = new Image();
img.src = URL.createObjectURL(file);
img.onload = () => {
const canvas = document.querySelector('canvas');
canvas.width = img.width;
canvas.height = img.height;
const ctx = canvas.getContext('2d');
ctx.drawImage(img, 0, 0);
ctx.strokeStyle = '#00FF00';
ctx.lineWidth = 3;
ctx.font = '18px serif';
boxes.forEach(([x1, y1, x2, y2, label]) => {
ctx.strokeRect(x1, y1, x2 - x1, y2 - y1);
ctx.fillStyle = '#00ff00';
const width = ctx.measureText(label).width;
ctx.fillRect(x1, y1, width + 10, 25);
ctx.fillStyle = '#000000';
ctx.fillText(label, x1, y1 + 18);
});
};
}
</script>
</body>
</html>
HTML-часть очень мала и состоит только из поля ввода файла с идентификатором “uploadInput” и элемента canvas под ним.
Затем в JavaScript-части “onChange” мы определяем обработчик события для поля ввода. Когда пользователь выбирает файл изображения, обработчик с помощью функции fetch выполняет POST-запрос к конечной точке /detect backend (которую мы создадим позже) и отправляет ей этот файл изображения.
Бэкэнд должен обнаружить объекты на этом изображении и вернуть ответ с массивом боксов в формате JSON. Этот ответ декодируется и передается в функцию draw_image_and_boxes вместе с файлом изображения.
Функция draw_image_and_boxes загружает изображение из файла. Сразу после загрузки она рисует его на холсте. Затем поверх холста с изображением рисуется каждая ограничивающая рамка с меткой класса.
Итак, теперь давайте создадим бэкенд с конечной точкой /detect для него.
Как создать бэкенд
Мы создадим бэкенд с помощью Flask. Flask имеет свой собственный внутренний веб-сервер, но, по мнению многих разработчиков Flask, он недостаточно надежен для productio. Поэтому мы будем использовать веб-сервер Waitress и запускать наше приложение Flask на нем.
Кроме того, мы будем использовать библиотеку Pillow для чтения загруженных бинарных файлов в виде изображений. Прежде чем продолжить, убедитесь, что все эти пакеты установлены в вашей системе:
pip3 install flask
pip3 install waitress
pip3 install pillow
Бэкэнд будет находиться в одном файле. Назовем его object_detector.py:
from ultralytics import YOLO
from flask import request, Response, Flask
from waitress import serve
from PIL import Image
import json
app = Flask(__name__)
@app.route("/")
def root():
"""
Site main page handler function.
:return: Content of index.html file
"""
with open("index.html") as file:
return file.read()
@app.route("/detect", methods=["POST"])
def detect():
"""
Handler of /detect POST endpoint
Receives uploaded file with a name "image_file",
passes it through YOLOv8 object detection
network and returns an array of bounding boxes.
:return: a JSON array of objects bounding
boxes in format
[[x1,y1,x2,y2,object_type,probability],..]
"""
buf = request.files["image_file"]
boxes = detect_objects_on_image(Image.open(buf.stream))
return Response(
json.dumps(boxes),
mimetype='application/json'
)
def detect_objects_on_image(buf):
"""
Function receives an image,
passes it through YOLOv8 neural network
and returns an array of detected objects
and their bounding boxes
:param buf: Input image file stream
:return: Array of bounding boxes in format
[[x1,y1,x2,y2,object_type,probability],..]
"""
model = YOLO("best.pt")
results = model.predict(buf)
result = results[0]
output = []
for box in result.boxes:
x1, y1, x2, y2 = [
round(x) for x in box.xyxy[0].tolist()
]
class_id = box.cls[0].item()
prob = round(box.conf[0].item(), 2)
output.append([
x1, y1, x2, y2, result.names[class_id], prob
])
return output
serve(app, host='0.0.0.0', port=8080)
Сначала мы импортируем необходимые библиотеки:
- ultralytics для модели YOLOv8.
- flask для создания веб-приложения Flask, которое будет принимать запросы от фронтенда и отправлять ему ответы.
- waitress для запуска веб-сервера и обслуживания на нем веб-приложения Flask.
- PIL для загрузки загруженного файла в виде объекта Image, что необходимо для YOLOv8.
- json для преобразования массива ограничительных рамок в JSON перед возвратом его на фронтенд.
Затем мы определили два маршрута:
- /, который служит корнем веб-сервиса. Он просто возвращает содержимое файла “index.html”.
- /detect, который отвечает на запрос загрузки изображения с фронтенда. Он преобразует RAW-файл в объект Pillow Image, а затем передает это изображение функции detect_objects_on_image. Функция detect_objects_on_image создает объект модели на основе модели best.pt, которую мы обучали в предыдущем разделе. Убедитесь, что этот файл существует в папке, где вы пишете код.
Затем она вызывает метод predict для изображения. predict возвращает обнаруженные ограничивающие рамки.
Далее для каждой рамки извлекаются координаты, имя класса и вероятность, как мы делали это в начале урока. Эта информация добавляется в выходной массив.
Наконец, функция возвращает массив обнаруженных координат объектов и их классов.
После этого массив кодируется в JSON и возвращается на фронтенд.
Последняя строка кода запускает веб-сервер на порту 8080, который обслуживает приложение Flask.
Чтобы запустить сервис, выполните следующую команду:
python3 object_detector.py
Если все работает правильно, можно открыть http:///localhost:8080 в веб-браузере. На экране должна появиться страница index.html. При выборе любого файла изображения она будет обрабатывать его и выводить ограничительные рамки вокруг всех обнаруженных объектов (или просто выводить изображение, если на нем ничего не обнаружено).
Только что созданный нами веб-сервис является универсальным. Вы можете использовать его с любой моделью YOLOv8. В данный момент он определяет светофоры и дорожные знаки, используя созданную нами модель best.pt. Но вы можете изменить ее, чтобы использовать другую модель, например, модель yolov8m.pt, которую мы использовали ранее для обнаружения кошек, собак и всех других классов объектов, которые могут обнаруживать предварительно обученные модели YOLOv8.
Заключение
В этом руководстве я рассказал вам о процессе создания веб-приложения с поддержкой искусственного интеллекта, использующего YOLOv8, современную конволюционную нейронную сеть для обнаружения объектов.
Я показал, как создавать модели с использованием предварительно обученных моделей и подготавливать данные для обучения пользовательских моделей. И наконец, мы создали веб-приложение с фронтендом и бэкендом, которое использует обученную модель YOLOv8 для обнаружения светофоров и дорожных знаков.
Исходный код этого приложения можно найти в этом репозитории GitHub.
Для решения всех этих задач мы использовали высокоуровневые API Ultralytics, которые по умолчанию поставляются с пакетом YOLOv8. Эти API основаны на фреймворке PyTorch, который использовался для создания большей части современных нейронных сетей.
С одной стороны, это достаточно удобно, но зависимость от этих высокоуровневых API имеет и негативный эффект. Если вам нужно запустить это веб-приложение в продакшене, то необходимо установить туда все эти среды, включая Python, PyTorch и другие зависимости.
Чтобы запустить его на новом чистом сервере, вам придется скачать и установить более 1 ГБ сторонних библиотек! Это определенно не самый отличный вариант.
Кроме того, что делать, если в вашей рабочей среде нет Python? А если весь остальной код написан на другом языке программирования, и вы не планируете использовать Python? Или если вы хотите запустить модель на мобильном телефоне с операционной системой Android или iOS?
Все это говорит о том, что использование пакетов Ultralytics отлично подходит для экспериментов, обучения и подготовки моделей к производству. Но в самом производстве необходимо загружать и использовать модель напрямую, не прибегая к помощи высокоуровневых API.
Для этого необходимо понять, как работает нейронная сеть YOLOv8 “под капотом”, и написать больше кода для подачи входных данных в модель и обработки полученных от нее результатов. Это позволит сделать ваши приложения более быстрыми и менее ресурсоемкими. Для запуска модели обнаружения объектов не требуется установка PyTorch.
Кроме того, вы сможете запускать свои модели даже без Python, используя многие другие языки программирования, включая Julia, C++, Go, Node.js на бэкенде или вообще без бэкенда. Вы можете запускать модели YOLOv8 прямо в браузере, используя только JavaScript на фронтенде.
Хотите узнать, как это делается? Этому будет посвящена моя следующая статья о YOLOv8.
Успехов вам в кодинге и не переставайте учиться!