
В ноябре 2021 года Render представил бесплатный уровень для разработчиков-любителей и команд, желающих попробовать свои силы. Число пользователей росло устойчивыми и предсказуемыми темпами, пока через десять месяцев компания Heroku не объявила о прекращении предоставления бесплатного уровня:
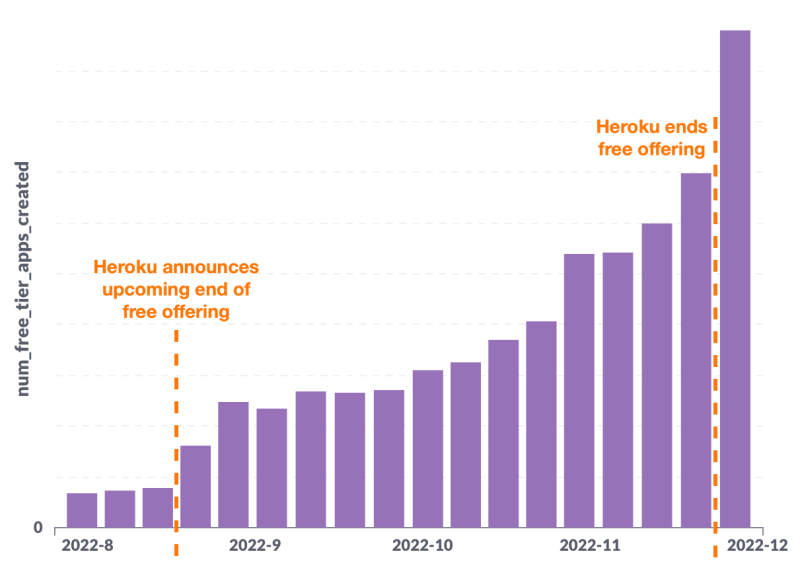
Число пользователей Render на свободных уровнях сразу удвоилось и стало расти дальше (что удивительно), в результате чего наша инфраструктура начала поскрипывать под нагрузкой (что менее удивительно). В течение месяца мы столкнулись с четырьмя инцидентами, связанными с этим ростом. Мы понимали, что если использование Free будет продолжать расти (а оно очень сильно растет — на данный момент еженедельно создаются десятки тысяч приложений на свободном уровне), то нам необходимо сделать его более масштабируемым. В этой заметке описывается первый шаг, который мы сделали на этом пути.
Оглавление
Как мы изначально создавали Free
Немного предыстории: в отличие от других сервисов на Render, веб-сервисов free-tier ”масштабируются до нуля” (то есть прекращают работу), если они 15 минут не получают трафик. Они запускаются снова, как только получают следующий входящий запрос. Такое поведение “спящего режима” позволяет нам предоставлять бесплатное предложение, не разоряясь при этом.
Однако такое поведение сразу вызвало трудности при разработке. Render использует Kubernetes (K8s) за кулисами, а K8s не поддерживал масштабирование до нуля (и не поддерживает до сих пор, по состоянию на сентябрь 2023 года). В поисках подходящего решения мы остановились на Knative (kay-NAY-tiv). Knative расширяет Kubernetes за счет поддержки бессерверных технологий — это естественный вариант для сервисов, которые должны регулярно запускаться и разворачиваться.
В интересах быстрой доставки мы развернули Knative с конфигурацией по умолчанию. И до тех пор, пока спустя почти год не произошел скачок нашего роста, эти настройки работали без проблем.
Где мы натолкнулись на стену
С ростом числа бесплатных уровней общее количество приложений на Render фактически увеличилось в четыре раза. Это привело к значительной нагрузке на сетевой уровень каждого из наших кластеров Kubernetes. Чтобы понять природу этой нагрузки, давайте посмотрим, как работает этот уровень.
На каждом узле каждого кластера работают два сетевых компонента: Calico и kube-proxy.
Calico в основном занимается управлением IP-адресами, или IPAM: назначением IP-адресов подсам и сервисам (мы используем заглавную букву Service для обозначения сервиса Kubernetes, чтобы отличить его от сервисов, которые клиенты создают на Render). Он также обеспечивает соблюдение сетевых политик, управляя правилами iptables на узле.
Kube-proxy настраивает другой набор правил маршрутизации на узле для обеспечения балансировки нагрузки на трафик, предназначенный для сервиса, между всеми поддерживающими подсистемами.
Оба этих компонента выполняют свою работу, прослушивая создание, обновление и удаление всех Под и Сервисов в кластере. Как вы можете себе представить, наличие большего количества подсистем и сервисов, которые меняются чаще, приводит к увеличению объема работы:
- Больший объем работы означал большее потребление процессора. Помните, что и Calico, и kube-proxy работают на каждом узле. Чем больше CPU использовали эти компоненты, тем меньше у нас оставалось ресурсов для работы приложений наших клиентов.
- Большее количество работы означало более высокую задержку обновления. По мере роста очереди работ каждое сетевое изменение распространялось дольше из-за увеличения времени ожидания в очереди. Эта задержка определяется как задержка сетевого программирования, или NPL (подробнее о NPL можно прочитать здесь). При высокой NPL трафик мог направляться по устаревшим правилам, которые никуда не вели (Pod уже был уничтожен), что приводило к периодическим сбоям в соединениях.
- Чтобы уменьшить эти проблемы, нам нужно было снизить нагрузку, которую каждое приложение свободного уровня добавляло к нашему сетевому механизму.
"Serviceless" Knative
Как уже говорилось, мы развернули готовый Knative для работы с ресурсами свободного уровня. Мы внимательно посмотрели, какие именно примитивы K8s предоставляются каждому свободному приложению:
Один Pod (для выполнения кода приложения). Ожидается.
2N + 1 Services, где N - количество раз развертывания приложения. Это связано с тем, что Knative управляет изменениями с помощью Revisions и сохраняет ресурсы, принадлежащие историческим Revisions. Неожиданно.
Мы поняли, что Pod должен остаться, но действительно ли нам нужны все эти сервисы Kubernetes? Что, если мы могли бы обойтись меньшим числом или даже нулем?
Мы углубились в изучение того, как эти ресурсы взаимодействуют в кластере:

И узнали, для чего нужен каждый из сервисов, предоставляемых Knative (выделены фиолетовым цветом):
- Placeholder Service - это фиктивная служба, существующая для предотвращения коллизий в наименованиях ресурсов для приложений, управляемых Knative. По одной службе было на каждое приложение свободного уровня.
- Public Service маршрутизировал входящий трафик к приложению из публичного Интернета.
- Частный сервис маршрутизировал входящий трафик для локального кластера в зависимости от масштабирования приложения.
При увеличении масштаба трафик направлялся в Pod.
При уменьшении масштаба трафик направлялся на Knative-прокси кластера (так называемый активатор), который занимался масштабированием приложения путем создания Pod.
Вооружившись полученными знаниями, мы придумали, как удалить все эти службы.
Шаг за шагом
Мы начали с фиктивного сервиса Placeholder Service, который буквально ничего не делал. Риск коллизии имен среди наших ресурсов, управляемых Knative, отсутствовал, поэтому мы обновили контроллер Knative Route, чтобы он перестал создавать Placeholder Service. ❌
Далее! Хотя служба Public Service (для маршрутизации в публичном Интернете) необходима для многих случаев использования Knative, в Render-land все запросы из публичного Интернета должны проходить через наш уровень балансировки нагрузки. Это означает, что запросы гарантированно будут кластерно-локальными к тому моменту, когда они достигнут бодов, так что Public Service также ничего не нужно делать! Мы исправили Knative, чтобы он и связанные с ним ресурсы Endpoint перестали согласовываться. ❌
И, наконец, Private Service (для кластерно-локальной маршрутизации). Мы объединили понятия, что сервисы используются для балансировки нагрузки между резервными подсистемами, и, что в приложении свободного уровня одновременно может принимать трафик только одна подсистема, что делает балансировку нагрузки немного ненужной. Необходимо было внести два изменения:
Направить трафик исключительно через активатор, поскольку у нас больше не было службы, на которую можно было бы разделить трафик при увеличении масштаба приложения. Немного поэкспериментировав, мы обнаружили, что активатор может как пробуждать боды, так и обращать прокси на пробужденный бод, хотя такое поведение не было документировано! Нам просто нужно было установить правильные заголовки.
Настройте активатор на прослушивание изменений состояний готовности бодов и маршрутизацию непосредственно по IP-адресам бодов (спасибо, Calico!). По умолчанию активатор прослушивает изменения EndpointSlices, но они привязаны к сервисам, которые мы хотели удалить.
И вот так приватный сервис перестал существовать. ❌
Хотите заглянуть глубже под капот? Посмотрите сокращенную версию проектной документации по удалению Private Service.
В конце всего этого пути оптимизации сетевая архитектура для приложения свободного уровня была упрощена до следующего вида:

Ноль сервисов Kubernetes на одно приложение свободного уровня! Вполне предсказуемо, что количество сервисов K8s резко упало на всех наших кластерах:

Благодаря этим улучшениям суммарное использование Calico и kube-proxy снизилось на сотни процессорных секунд на нашем крупнейшем кластере.
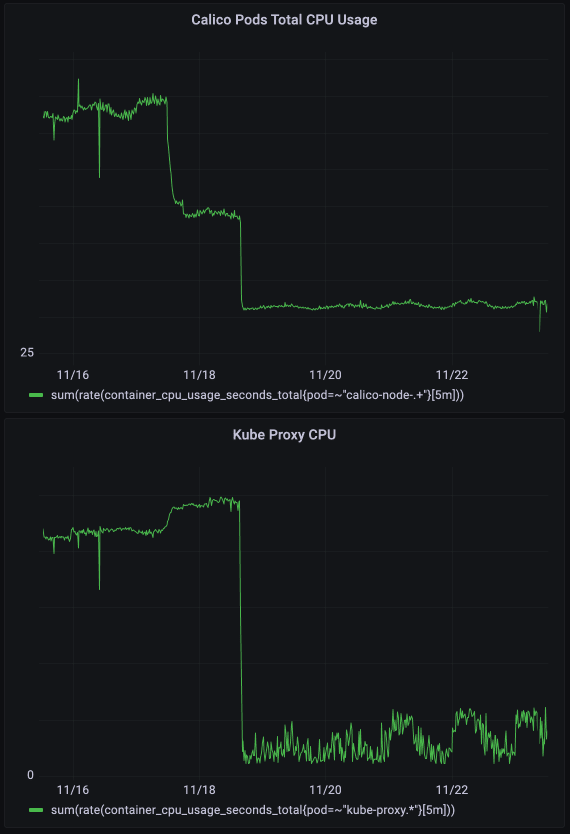
Благодаря высвобождению вычислительных ресурсов значительно улучшились показатели задержки и стабильности работы сети свободного уровня. Но даже в этом случае мы понимали, что нам еще есть над чем работать.
Движущаяся цель
Усовершенствования Knative позволили нам получить столь необходимую свободу действий, но в конечном итоге использование свободного уровня стало оказывать нагрузку даже на эту оптимизированную архитектуру. Настало время полностью отказаться от Knative в пользу собственного решения, специально разработанного для нужд Render.
Но это уже история для другого поста!