
Веб-скрейпинг, если говорить простым языком, - это техника, используемая для сбора полезных данных с веб-сайта. Согласитесь, в Интернете есть масса информации, и чаще всего она может быть структурирована не совсем так, как нам нужно. Таким образом, веб-скрейпинг позволяет нам извлекать данные из Интернета, которые затем можно реструктурировать или перестроить так, чтобы они были полезны для нас.
В этой статье я проведу вас шаг за шагом через процесс веб-скрейпинга, дам полезные советы по развитию ваших навыков, подскажу, что делать и чего не делать при скрейпинге веб-сайтов (в частности, о нарушении авторских прав), и многое другое. Кроме того, мы будем скреативить два сайта, CoinMarketCap и Bitcoin.com, чтобы получить цены на криптовалюты и последние новости о Bitcoin.
Оглавление
Необходимые условия
- Базовые навыки программирования. Хотя в этой статье мы будем использовать Python, вы сможете извлечь из нее пользу, даже если знакомы с другими языками программирования.
- Фундаментальное понимание HTML, элементов и атрибутов HTML и т.д.
- Знание Chrome DevTools (не обязательно)
- Компьютер или другой инструмент для выполнения кода Python.
Позвольте мне быстро познакомить вас с двумя пакетами: requests и BeautifulSoup. Это библиотеки Python, которые используются для соскабливания веб-сайтов. В этой статье они нам понадобятся.
Процесс веб-скрапинга
Когда вы заходите в браузер и вводите url сайта, который хотите посетить, ваш браузер делает запрос на сервер. Затем сервер отвечает вашему браузеру. Браузер получает данные от сервера в виде текста, HTML, JSON или многокомпонентного запроса (медиафайла).
Когда браузер получает HTML, он анализирует его, создает узлы DOM и отображает их на странице, выводя прекрасный веб-сайт на ваш экран.

При скрейпинге веб-сайтов нам нужен этот HTML-контент, и это знакомит нас с первыми пакетными запросами.
Запросы
Как следует из названия, он используется для отправки запросов на серверы. Если у вас есть опыт разработки фронтенда или Javascript, это эквивалент fetch API в Javascript.
Для того чтобы мы могли соскабливать содержимое сайта, нам нужно убедиться, что конечная точка сервера, к которой мы обращаемся, возвращает HTML.
После получения HTML следующим шагом будет сбор нужных нам данных. И это приводит нас ко второму пакету BeautifulSoup.
Beautiful Soup
Beautiful Soup - это библиотека, используемая для извлечения данных из HTML и XML файлов. Beautiful soup содержит множество очень полезных утилит, которые делают веб-скрейпинг действительно простым.
Создание скреперов (написание кода)
После долгих разговоров перейдем к самой сути дела - написанию кода и созданию собственно веб-скреперов.
Я создал репозиторий на Github, который содержит код для скреперов. Полный код находится в ветке completed, для начала работы перейдите в ветку get-started.
В этой статье я буду создавать проект с нуля, для тех, кто не хочет клонировать репозиторий Github.
НАСТРОЙКА ПРОЕКТА
- Создайте новую папку. Назовите ее как угодно.
- Создайте новое виртуальное окружение.
Выполните следующие команды для создания нового виртуального окружения
# if you've not already installed virtualenv
pip install virtualenv
# you can name your environment whatever you want
python -m venv <name_of_environment>
После успешного выполнения предыдущих команд вы должны увидеть папку с именем виртуальной среды, которую вы только что создали.
Вам также необходимо активировать виртуальную среду. Для этого выполните следующие команды в зависимости от вашей ОС.
# macOS / linux
source ./<virtual_env_name>/bin/activate
# windows
<virtual_env_name>/Scripts/activate.bat # In CMD
<virtual_env_name>/Scripts/Activate.ps1 # In Powershell
Установите необходимые пакеты.
Активировав нашу виртуальную среду, давайте перейдем к установке пакетов. Для этого выполните в терминале следующие действия:
pip install requests beautifulsoup4
Создайте файл requirements.txt.
Если вы будете делиться кодом с кем-то или командой, важно, чтобы другая сторона установила точно такую же версию пакета, которую вы использовали для сборки проекта. В используемом пакете могут быть изменения, поэтому важно, чтобы все использовали одну и ту же версию. Файл requirements.txt позволяет другим узнать точную версию пакетов, которые вы использовали в проекте.
Чтобы сгенерировать файл requirements.txt, просто выполните следующие действия:
pip freeze > requirements.txt
После выполнения этой команды вы должны увидеть файл, содержащий пакеты, необходимые для запуска проекта.
Если вы работаете в команде и в проекте есть файл requirements.txt, запустите pip install -r requirements.txt, чтобы установить точную версию пакетов из файла requirements.txt.
Сколько раз я сказал про файл requirements.txt? 🤡
Добавьте файл .gitignore.
Он используется для указания git’у файлов или папок, которые следует игнорировать при запуске git add. Добавьте /<virtual_env_name> в файл .gitignore.

Скраппинг Bitcoin.com
Теперь мы займемся скраппингом первого сайта. Первое, что нам нужно сделать, это получить HTML с запросами.
Итак, создайте файл bitcoinnews.py (вы можете назвать его как угодно).
Добавьте в файл следующий код
import requests
def get_news():
url = '<https://news.bitcoin.com>'
response = requests.get(url) # making a request
response_text = response.text # getting the html
# here's where we should get the news content from the html, we're just printing the content to the terminal for now
print(response_text)
get_news()
Немного о HTML и разработке фронтенда
При сканировании веб-сайтов важно понимать основы HTML, поскольку это поможет нам выбрать наилучший способ извлечения данных.
HTML (HyperText Markup Language) - это стандартный язык разметки для создания веб-страниц. HTML используется для описания структуры веб-страницы. Элементы HTML - это строительные блоки каждой веб-страницы. Элементы HTML связаны друг с другом таким образом, что напоминают дерево.

На схеме выше у нас есть корневой элемент, элемент <html>, который имеет два дочерних элемента, элементы <head> и <body>. У тега <head> есть один дочерний элемент, тег <, который имеет в качестве дочернего элемента простой текст. Элемент <body> имеет три дочерних элемента (один тег заголовка и два тега абзаца).
Эта древовидная структура облегчает компоновку элементов и определение отношений между ними. Это упрощает написание абзаца и включение в него ссылок.
Элементы HTML, помимо наличия дочерних элементов, имеют атрибуты, которые добавляют им гораздо больше функциональности. Элемент ‘image’ требует указания источника изображения, которое он должен отображать. Когда вы нажимаете на ссылку (тег якоря), он должен знать, куда вы хотите перейти. Атрибуты также могут использоваться для различения одного элемента и группы элементов.
Понимание атрибутов HTML очень важно, поскольку при сканировании веб-сайта нам нужны конкретные данные, и важно, чтобы мы могли нацелиться на элементы, содержащие нужные нам данные.
Если вы хотите узнать больше об HTML, вы можете посетить сайт W3schools.com.
Скраппинг лучших цен на криптовалюты с CoinMarketCap.
Прежде чем мы вернемся к нашему скреперу Bitcoin News, давайте соскребем цены ведущих криптовалют с CoinMarketCap вместе с изображениями.
СОВЕТ: Прежде чем приступить к скраппингу веб-сайта, отключите Javascript и откройте страницу в браузере. Это важно, потому что некоторые сайты отображают содержимое на веб-странице с помощью Javascript на стороне клиента, который не может быть использован нашими скреперами. Поэтому имеет смысл видеть только точный HTML, который возвращает сервер.
С запущенным Javascript

Без работающего Javascript

Если вы откроете сайт coinmarketcap.com в браузере с отключенным Javascript, вы заметите, что можете получить цены только на первые десять криптовалют. Вы также заметите, что в браузере, где включен Javascript, вы можете прокручивать страницу, чтобы получить цены на другие криптовалюты. Это различие во внешнем виде страницы (HTML) может доставить вам много неприятностей при скраппинге веб-сайта.
Вернемся к редактору кода
- Создайте новый файл. Вы можете назвать его как угодно. Я назвал свой coinmarketcap.py
- Добавьте в него следующий код.
import requests
from bs4 import BeautifulSoup
def get_crypto_prices():
url = '<https://coinmarketcap.com>'
response_text = requests.get(url).text
soup = BeautifulSoup(response_text, 'html.parser') #added this line
print(soup)
get_crypto_prices()
Этот файл выглядит почти так же, как предыдущий, я только изменил URL и название функции, а также добавил строку с BeautifulSoup.
Эта строка кода анализирует HTML-текст, который мы получаем от конечной точки, и преобразует его в объект BeautifulSoup, который имеет методы, которые мы можем использовать для извлечения информации из текста.
Теперь, когда у нас есть доступ к HTML, давайте разберемся, как извлечь нужные нам данные: в нашем случае цены на криптовалюты.
Откройте DevTools в своем веб-браузере.
Если вы используете Chrome на Mac, вы можете нажать Cmd + Option + I, чтобы открыть DevTools.
Или вы можете просто щелкнуть правой кнопкой мыши на целевом элементе и нажать кнопку inspect.

Если вы посмотрите на элементы в разделе Inspect Element в Chrome DevTools, вы заметите, что там есть элемент table с дочерними элементами. Внутри элемента таблицы есть элементы colgroup, thead, tbody. Элемент tbody содержит все содержимое таблицы. Внутри элемента tbody есть элемент tr, обозначающий строку таблицы, который также содержит несколько элементов td. td обозначает данные таблицы.
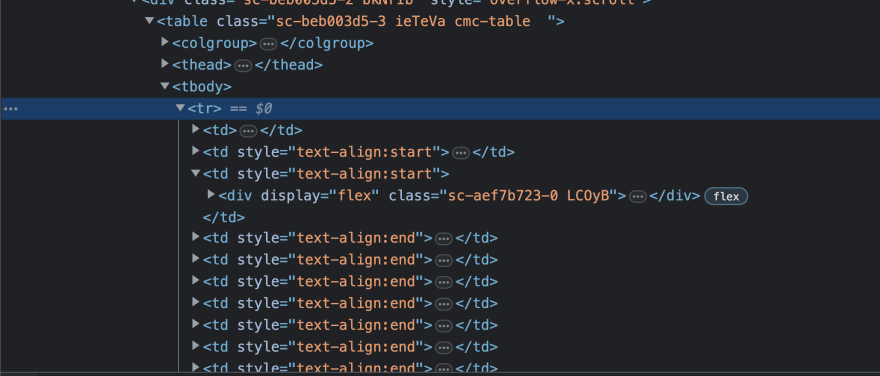
Теперь просто знать, что нужные нам данные находятся в таблице, недостаточно. Мы должны углубиться в дерево HTML, чтобы извлечь именно те данные, которые нам нужны. В данном случае нам нужно название криптовалюты, сокращенное название, например, BTC для Bitcoin, текущая цена и изображение криптовалюты.

Если присмотреться, можно заметить, что название криптовалюты находится в теге параграфа с классом sc-e225a64a-0 ePTNty. Сокращенное название криптовалюты также находится в теге абзаца с другим именем класса sc-e225a64a-0 dfeAJi coin-item-symbol.
Мы используем такие атрибуты, как class и id, для уникальной идентификации элементов HTML или групп знакомых элементов HTML. Когда у нас есть эти уникальные атрибуты, мы можем использовать их для нацеливания на элементы и извлечения из них нужных нам значений.
Что мы уже сделали?
Проанализировав сайт Coinmarketcap, мы увидели, что данные о каждой криптовалюте расположены в строке, и каждая строка имеет дочерние элементы, содержащие данные, которые мы хотим извлечь.
Давайте вернемся к редактору кода и обновим наш файл coinmarketcap.py
import requests
from bs4 import BeautifulSoup
def get_crypto_prices():
url = '<https://coinmarketcap.com>'
response_text = requests.get(url).text
soup = BeautifulSoup(response_text, 'html.parser')
# get all the table rows
table_rows = soup.findAll('tr')
# iterate through all the table rows and get the required data
for table_row in table_rows:
crypto_name = table_row.find('p', class_ = 'sc-e225a64a-0 ePTNty')
shortened_crypto_name = table_row.find('p', class_ = 'sc-e225a64a-0 dfeAJi coin-item-symbol')
coin_img = table_row.find('img', class_ = 'coin-logo')
print(crypto_name, shortened_crypto_name)
get_crypto_prices()
Обратите внимание на разницу между findAll и find
Если вы выполните приведенный выше код, то получите следующее

Вы можете видеть, что некоторые данные возвращают значение None. Это происходит из-за того, что оставшиеся строки таблицы пусты. Что мы можем сделать в этом случае, так это проверить, есть ли значение, прежде чем печатать значения.
Обновив наш цикл for, мы получим следующее:
# iterate through all the table rows and get the required data
for table_row in table_rows:
crypto_name = table_row.find('p', class_ = 'sc-e225a64a-0 ePTNty')
shortened_crypto_name = table_row.find('p', class_ = 'sc-e225a64a-0 dfeAJi coin-item-symbol')
coin_img = table_row.find('img', class_ = 'coin-logo')
if crypto_name is None or shortened_crypto_name is None:
continue
else:
crypto_name = crypto_name.text
shortened_crypto_name = shortened_crypto_name.text
coin_img = coin_img.attrs.get('src')
print(crypto_name, shortened_crypto_name)
Если есть значение crypto_name или shortened_crypto_name, мы получаем текст из HTML-элемента и выводим его в консоль. Мы также получаем src изображения криптовалюты.
Запустив обновленный код, мы должны получить следующее:

Теперь давайте получим цены для каждой криптовалюты.
Вернувшись в Chrome Devtools и щелкнув правой кнопкой мыши на тексте цены, мы должны увидеть следующее:

Мы видим, что цена валюты находится в теге span, который обернут в тег якоря: тег a, который имеет значение класса cmc-link. Однако использование класса тега якоря для поиска цены не сработает, потому что класс cmc-link не идентифицирует элемент, на который мы пытаемся нацелиться.
const bitcoinRow = document.querySelectorAll('tr')[1]
const cmcLinks = bitcoinRow.querySelectorAll('.cmc-link')
console.log(cmcLinks) // NodeList(4) [a.cmc-link, a.cmc-link, a.cmc-link, a.cmc-link]
Если вы запустите приведенный выше код Javascript в консоли браузера, вы увидите, что в каждом ряду есть четыре ссылки с именем класса cmc-link. Это определенно не лучший способ получить цену криптовалюты в данном ряду.
Давайте посмотрим на родителя: div с именем класса sc-8bda0120-0 dskdZn
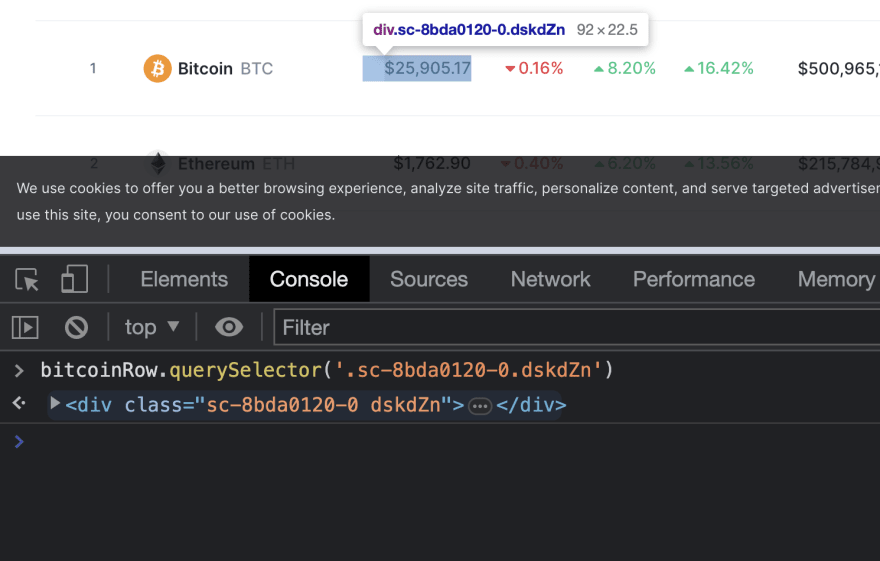
Обратите внимание, что при наведении элемента на консоль цена также наводится на веб-страницу. Таким образом, это оказывается лучшим способом получения цены криптовалюты.
Обновив код, мы получили:
import requests
from bs4 import BeautifulSoup
def get_crypto_prices():
url = '<https://coinmarketcap.com>'
response_text = requests.get(url).text
soup = BeautifulSoup(response_text, 'html.parser')
# get all the table rows
table_rows = soup.findAll('tr')
# iterate through all the table rows and get the required data
for table_row in table_rows:
crypto_name = table_row.find('p', class_ = 'sc-e225a64a-0 ePTNty')
shortened_crypto_name = table_row.find('p', class_ = 'sc-e225a64a-0 dfeAJi coin-item-symbol')
coin_img = table_row.find('img', class_ = 'coin-logo')
crypto_price = table_row.find('div', class_ = 'sc-8bda0120-0 dskdZn')
if crypto_name is None or shortened_crypto_name is None or crypto_price is None:
continue
else:
crypto_name = crypto_name.text
shortened_crypto_name = shortened_crypto_name.text
coin_img = coin_img.attrs.get('src')
crypto_price = crypto_price.text
print(f"Name: {crypto_name} ({shortened_crypto_name}) \\nPrice: {crypto_price} \\nImage URL: {crypto_img_url}\\n")
get_crypto_prices()
Запустив обновленный код, мы должны получить следующее:

Ууууппппсссссссс… Это было очень сложно. Надеюсь, вы смогли довести дело до конца.
Возьмите чашку кофе, вы ее заслужили👍.
Возвращаясь к скрапбукингу Bitcoin News
Теперь, вооружившись знаниями, которые мы получили от скраппинга Coinmarketcap, мы можем продолжить работу над скраппером Bitcoin News. Мы будем использовать этот скребок для получения последних новостей в криптовалютном пространстве.
Щелкнув правой кнопкой мыши на первой новости и открыв раздел Inspect Elements в Chrome Devtools, мы увидим, что заголовки новостей имеют класс story. Однако если вы щелкните правой кнопкой мыши на других новостных заголовках, то обнаружите, что они имеют разновидности. Есть средняя история, маленькая, огромная, крошечная и т.д., с разными названиями классов для уникальной идентификации каждого типа.
Очень важным навыком, необходимым для веб-скраппинга, является способность внимательно изучить структуру HTML веб-страницы. Если вы понимаете структуру веб-страницы, то извлечение полезного содержимого из элементов не представляет собой сложной задачи.
Возвращаемся к редактору кода:
import requests
def get_news():
url = '<https://news.bitcoin.com>'
response = requests.get(url) # making a request
response_text = response.text # getting the html
print(response_text)
soup = BeautifulSoup(response_text, 'html.parser')
all_articles = soup.findAll('div', class_ = 'story')
for article in all_articles:
print(article.text.strip())
get_news()
Когда вы запустите приведенный выше код, вы можете получить следующее:
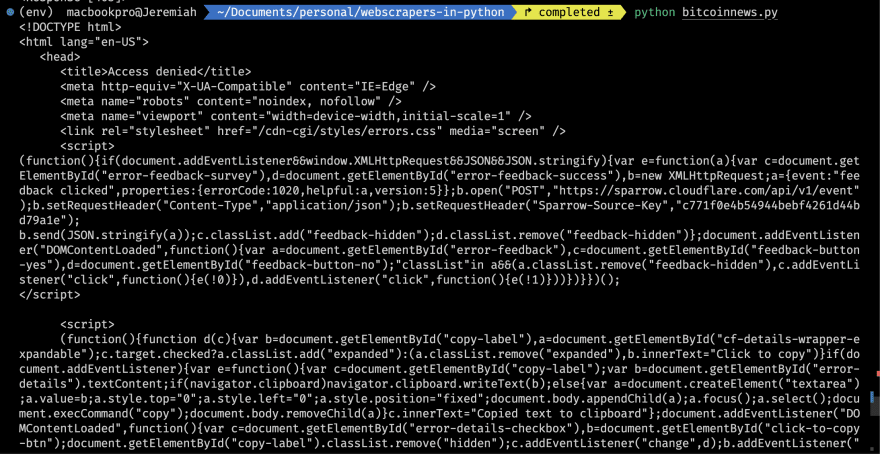
Чтобы предотвратить доступ вредоносных ботов к своему сайту, некоторые сайты используют Cloudflare Bot Management. Cloudflare ведет список известных хороших ботов, которым разрешен доступ к сайту, например, поисковые системы, боты для защиты авторских прав, боты для чата, боты для мониторинга сайта и так далее. К сожалению для таких энтузиастов веб-скрапинга, как мы с вами, они также предполагают, что весь трафик ботов, не включенных в белый список, является вредоносным.
Однако есть несколько способов обойти эту проблему, и легкость зависит от того, насколько бот представляет угрозу для Cloudflare и от плана Bot Protection, на который подписался владелец сайта.
Список способов обхода Cloudflare можно найти здесь. Щелкните здесь, чтобы узнать больше об управлении ботами Cloudflare.
В этой статье мы рассмотрим самое основное - установку заголовка User-Agent. Этим мы делаем вид, что запрос поступает от обычного браузера.
def get_news():
url = '<https://news.bitcoin.com>'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
}
response = requests.get(url, headers=headers)
# the rest of the code
После добавления приведенной выше строки кода и ее запуска мы должны получить следующее:
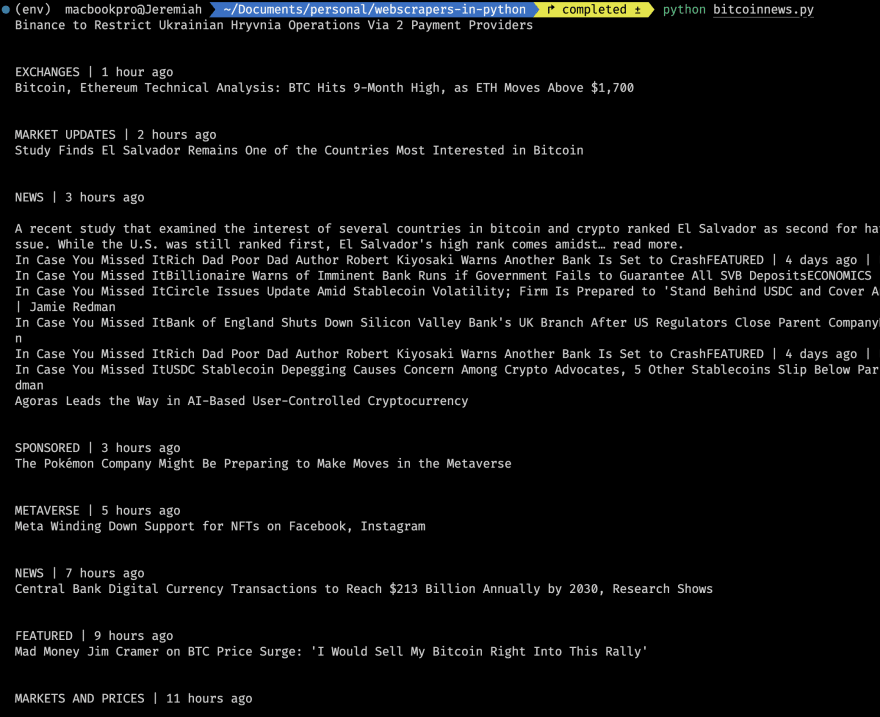
Теперь, когда у нас есть фактический веб-контент, давайте перейдем в наш браузер, чтобы просмотреть веб-страницу:
Щелкнув правой кнопкой мыши на первой новости, мы увидим следующее:
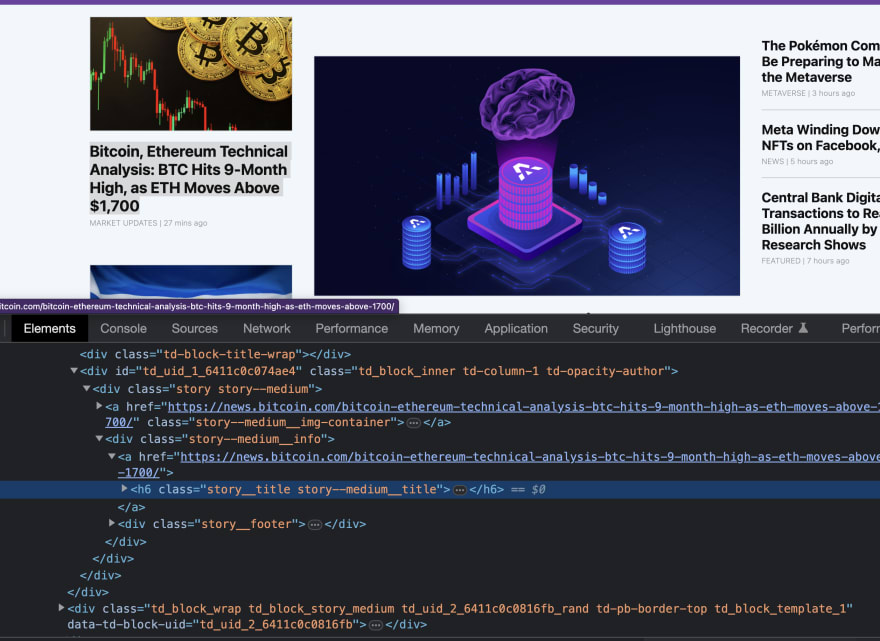
Скраппинг заголовка новостей
Обратите внимание, что элемент h6 имеет класс storytitle story–mediumtitle. Если вы щелкните правой кнопкой мыши на другой новости, вы можете увидеть что-то вроде storytitle story–hugetitle или storytitle story–largetitle. Заметьте, что уже существует закономерность: заголовок каждой новости всегда имеет класс story__title. Это кажется лучшим способом нацелиться на заголовок новости.
Скраппинг URL-адресов новостей
Если вы присмотритесь, то заметите, что у заголовка новости есть родитель, который является ссылкой. Эта ссылка содержит URL новости в атрибуте href.
Собрав все это вместе, мы можем написать код для скрепера.
import requests
from bs4 import BeautifulSoup
def get_news():
url = '<https://news.bitcoin.com>'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
} # headers to bypass Cloudflare Protection
response = requests.get(url, headers=headers)
response_text = response.text
soup = BeautifulSoup(response_text, 'html.parser')
all_articles = soup.findAll('div', class_ = 'story')
for article in all_articles:
news_title_element = article.select_one('.story__title')
news_url = news_title_element.parent.attrs.get('href')
news_title = news_title_element.text.strip()
print(f"HEADLINE: {news_title} \\nURL: {news_url}\\n")
get_news()
Выполнив приведенный выше код, мы получим заголовок новости и URL-адрес

Использование соскобленных данных
Теперь, когда мы успешно собрали необходимые данные с веб-сайтов, давайте сохраним собранные данные. Если вы работаете с базой данных, вы можете сразу сохранить ее в данных, вы можете выполнить вычисления с данными, вы можете сохранить их для будущего использования, как бы то ни было, данные, которые вы соскребли, не очень полезны в консоли.
Давайте сделаем что-то действительно простое: сохраним данные в JSON-файл
import requests
from bs4 import BeautifulSoup
import json
# some code
all_articles = soup.findAll('div', class_ = 'story')
scraped_articles = []
for article in all_articles:
news_title_element = article.select_one('.story__title')
news_url = news_title_element.parent.attrs.get('href')
news_title = news_title_element.text.strip()
scraped_articles.append({
"headline": news_title,
"url": news_url
})
with open ('news.json', 'w') as file:
news_as_json = json.dumps({
'news': scraped_articles,
'number_of_news': len(scraped_articles)
}, indent = 3, sort_keys = True)
file.write(news_as_json)
Теперь мы сохраняем сохраненные новости в JSON-файл, который можно использовать для любых целей.
Ваш JSON-файл должен выглядеть примерно так.
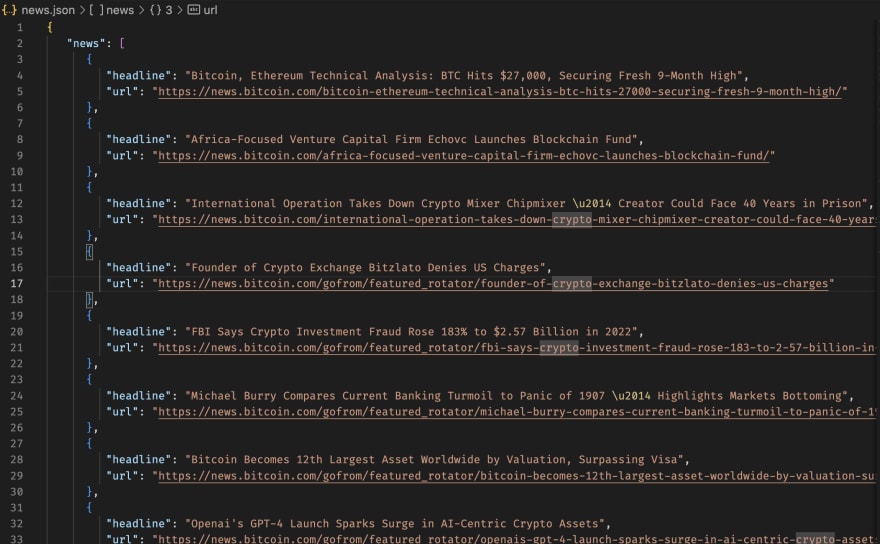
Whooopppsssss.⚡️⚡️ Это было очень много для восприятия.
Чего не следует делать при соскабливании веб-сайтов
Перегружать серверы слишком большим количеством запросов одновременно. Причина, по которой многие сайты не одобряют ботов, заключается в частом злоупотреблении ими. Когда вы делаете запрос, сервер использует ресурсы, чтобы обработать его. Большое количество запросов может привести к тому, что у сервера закончатся ресурсы, а это нехорошо.
"""
⛔️ DON'T DO THIS
"""
for i in range(10000):
request.get('<https://reallyamazingwebsite.com>')
Ваш IP-адрес может попасть в черный список.
Пренебрежение правилами авторского права. Веб-скрейпинг является абсолютно законным, если вы используете данные, находящиеся в открытом доступе в Интернете. Но некоторые виды данных защищены международными нормами, поэтому будьте осторожны при соскабливании личных данных, интеллектуальной собственности или конфиденциальных данных. Некоторые сайты могут открыто заявлять, что содержимое страницы не должно распространяться никакими другими способами, это следует уважать.
Наконец-то вы добрались до конца статьи, молодец, чемпион.
Заключение
В заключение хочу сказать, что веб-скрейпинг в Python может быть полезным инструментом для сбора информации с веб-сайтов для различных целей. Python предоставляет удобный и эффективный способ извлечения структурированных данных с веб-сайтов с помощью популярных библиотек, таких как BeautifulSoup. Однако важно помнить, что сбор информации с веб-сайтов всегда должен осуществляться этично и в соответствии с условиями обслуживания веб-сайта. Также важно знать о любых юридических ограничениях, которые могут применяться к данным, которые собираются. Учитывая эти факторы, веб-скрейпинг в Python может стать полезным навыком для всех, кто хочет собирать и анализировать данные из Интернета.
Если вам понравилось читать эту статью, вы можете поделиться ею в своих социальных сетях и следить за мной в социальных сетях.