
Посмотрев на Youtube видеоролик ”Как работают рекомендательные системы (Netflix/Amazon)” от Art of the Problem, я вдохновился им и захотел создать статью в блоге на эту тему. Итак, здесь мы будем работать над тем, как создать рекомендательную систему с помощью базы данных графов. Для этого мы будем использовать Apache AGE, который является расширением с открытым исходным кодом для PostgreSQL, позволяющим нам создавать узлы и ребра.
Оглавление
Создание графа
Учитывая наблюдения за действиями пользователей в прошлом, нам нужно предсказать, что еще может понравиться пользователю. Мы можем представить предпочтения пользователей графически в виде связей между людьми и вещами, которые они оценивают или о которых имеют мнение, например, фильмами. Подход, который мы будем использовать, называется фильтрацией содержимого, которая использует информацию, известную нам о людях и вещах, в качестве соединительной ткани для рекомендаций.
-- Creating the graph.
SELECT create_graph('RecommenderSystem');
-- Adding user.
SELECT * FROM cypher('RecommenderSystem', $
CREATE (:Person {name: 'Abigail'})
$) AS (a agtype);
-- Adding movies.
SELECT * FROM cypher('RecommenderSystem', $
CREATE (:Movie {title: 'The Matrix'}),
(:Movie {title: 'Shrek'}),
(:Movie {title: 'The Blair Witch Project'}),
(:Movie {title: 'Jurassic Park'}),
(:Movie {title: 'Thor: Love and Thunder'})
$) AS (a agtype);
-- Adding categories.
SELECT * FROM cypher('RecommenderSystem', $
CREATE (:Category {name: 'Action'}),
(:Category {name: 'Comedy'}),
(:Category {name: 'Horror'})
$) AS (a agtype);
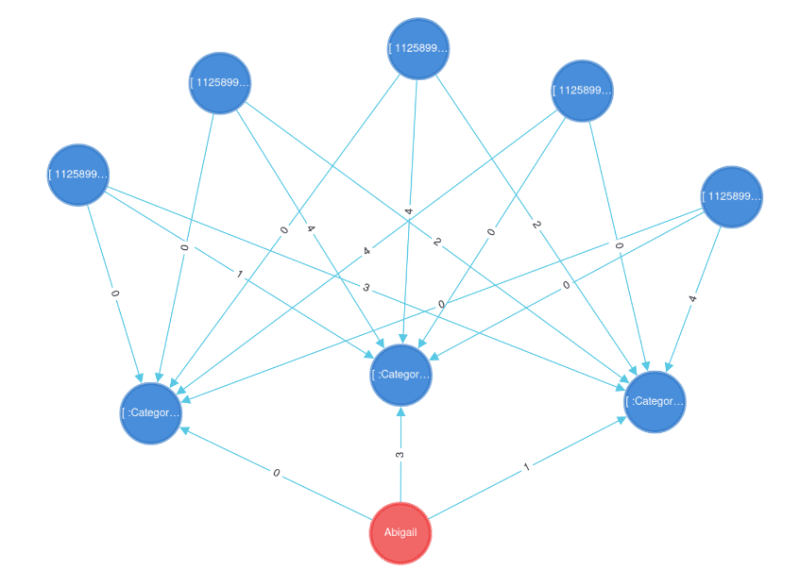
Мы можем представить силу связей с помощью свойства под названием рейтинг на ребрах между пользователями и категориями, а также фильмами и категориями. Этот рейтинг будет варьироваться от 0 до 4, где 0 означает, что пользователь ненавидел фильм, а 4 - что фильм ему понравился. Это также работает для категорий и фильмов, где 0 - меньшая вероятность, а 4 - наибольшая вероятность.
Допустим, Эбигейл имеет рейтинг 3 для комедии, 1 для боевика и 0 для ужасов.
-- User preferences.
SELECT * FROM cypher('RecommenderSystem', $
MATCH (a:Person {name: 'Abigail'}), (A:Category), (C:Category), (H:Category)
WHERE A.name = 'Action' AND C.name = 'Comedy' AND H.name = 'Horror'
CREATE (a)-[:RATING {rating: 3}]->(C),
(a)-[:RATING {rating: 1}]->(A),
(a)-[:RATING {rating: 0}]->(H)
$) AS (a agtype);
Каждый фильм также сопоставлен с каждой категорией таким же образом. Например, в ”Матрице” нет комедии, много экшена и нет ужасов.
-- The Matrix and it's relationship with Categories.
SELECT * FROM cypher('RecommenderSystem', $
MATCH (matrix:Movie {title: 'The Matrix'}), (A:Category), (C:Category), (H:Category)
WHERE A.name = 'Action' AND C.name = 'Comedy' AND H.name = 'Horror'
CREATE (matrix)-[:RATING {rating: 0}]->(C),
(matrix)-[:RATING {rating: 4}]->(A),
(matrix)-[:RATING {rating: 0}]->(H)
$) AS (a agtype);
-- Shrek and it's relationship with Categories.
SELECT * FROM cypher('RecommenderSystem', $
MATCH (shrek:Movie {title: 'Shrek'}), (A:Category), (C:Category), (H:Category)
WHERE A.name = 'Action' AND C.name = 'Comedy' AND H.name = 'Horror'
CREATE (shrek)-[:RATING {rating: 4}]->(C),
(shrek)-[:RATING {rating: 2}]->(A),
(shrek)-[:RATING {rating: 0}]->(H)
$) AS (a agtype);
-- The Blair Witch Project and it's relationship with Categories.
SELECT * FROM cypher('RecommenderSystem', $
MATCH (witch:Movie {title: 'The Blair Witch Project'}), (A:Category), (C:Category), (H:Category)
WHERE A.name = 'Action' AND C.name = 'Comedy' AND H.name = 'Horror'
CREATE (witch)-[:RATING {rating: 0}]->(C),
(witch)-[:RATING {rating: 0}]->(A),
(witch)-[:RATING {rating: 4}]->(H)
$) AS (a agtype);
-- Jurassic Park and it's relationship with Categories.
SELECT * FROM cypher('RecommenderSystem', $
MATCH (jurassic:Movie {title: 'Jurassic Park'}), (A:Category), (C:Category), (H:Category)
WHERE A.name = 'Action' AND C.name = 'Comedy' AND H.name = 'Horror'
CREATE (jurassic)-[:RATING {rating: 1}]->(C),
(jurassic)-[:RATING {rating: 3}]->(A),
(jurassic)-[:RATING {rating: 0}]->(H)
$) AS (a agtype);
-- Thor: Love and Thunder and it's relationship with Categories.
SELECT * FROM cypher('RecommenderSystem', $
MATCH (thor:Movie {title: 'Thor: Love and Thunder'}), (A:Category), (C:Category), (H:Category)
WHERE A.name = 'Action' AND C.name = 'Comedy' AND H.name = 'Horror'
CREATE (thor)-[:RATING {rating: 4}]->(C),
(thor)-[:RATING {rating: 2}]->(A),
(thor)-[:RATING {rating: 0}]->(H)
$) AS (a agtype);
Метод фильтрации содержимого
Чтобы определить, понравится ли кому-то фильм, нужно перемножить все факторы вместе и разделить их на количество категорий, умноженное на 4.
-- The Matrix estimated rating for the user.
SELECT e1/(ct*4) AS factor FROM cypher('RecommenderSystem', $
MATCH (u:Person)-[e1:RATING]->(v:Category)<-[e2:RATING]-(w:Movie{title: 'The Matrix'}), (c:Category) WITH e1, e2, COUNT(*) AS ct
RETURN SUM(e1.rating * e2.rating)::float, ct
$) AS (e1 float, ct agtype);
factor
-------------------
0.333333333333333
(1 row)
Мы можем представить силу связи между Эбигейл и Матрицей как: [(3 x 0) + (1 x 4) + (0 x 0)] / 12 = 0,3 . По нашим оценкам, фильм ей не очень понравится. Теперь нам нужно собрать данные по всем остальным фильмам, чтобы мы могли показать те, которые больше всего соответствуют ее интересам.
-- Shrek's estimated rating for the user.
SELECT e1/(ct*4) AS factor FROM cypher('RecommenderSystem', $
MATCH (u:Person)-[e1:RATING]->(v:Category)<-[e2:RATING]-(w:Movie{title: 'Shrek'}), (c:Category) WITH e1, e2, COUNT(*) AS ct
RETURN SUM(e1.rating * e2.rating)::float, ct
$) AS (e1 float, ct agtype);
factor
------------------
1.16666666666667
(1 row)
-- The Blair Witch Project estimated rating for the user.
SELECT e1/(ct*4) AS factor FROM cypher('RecommenderSystem', $
MATCH (u:Person)-[e1:RATING]->(v:Category)<-[e2:RATING]-(w:Movie{title: 'The Blair Witch Project'}), (c:Category) WITH e1, e2, COUNT(*) AS ct
RETURN SUM(e1.rating * e2.rating)::float, ct
$) AS (e1 float, ct agtype);
factor
--------
0.0
(1 row)
-- Jurassic Park estimated rating for the user.
SELECT e1/(ct*4) AS factor FROM cypher('RecommenderSystem', $
MATCH (u:Person)-[e1:RATING]->(v:Category)<-[e2:RATING]-(w:Movie{title: 'Jurassic Park'}), (c:Category) WITH e1, e2, COUNT(*) AS ct
RETURN SUM(e1.rating * e2.rating)::float, ct
$) AS (e1 float, ct agtype);
factor
--------
0.5
(1 row)
-- Thor: Love and Thunder estimated rating for the user.
SELECT e1/(ct*4) AS factor FROM cypher('RecommenderSystem', $
MATCH (u:Person)-[e1:RATING]->(v:Category)<-[e2:RATING]-(w:Movie{title: 'Thor: Love and Thunder'}), (c:Category) WITH e1, e2, COUNT(*) AS ct
RETURN SUM(e1.rating * e2.rating)::float, ct
$) AS (e1 float, ct agtype);
factor
------------------
1.16666666666667
(1 row)
Несмотря на то, что ”Шрек” и “Тор” не являются ее чашкой чая, согласно нашему анализу графиков, Эбигейл предпочтет посмотреть фильмы из нашего списка.
Заключение
Мы показали, как создать рекомендательную систему с графовой базой данных с помощью Apache AGE. Этот подход может быть расширен для реализации более сложных сценариев, таких как включение демографических данных пользователя, истории поиска или связей в социальных сетях. Графовые базы данных хорошо подходят для рекомендательных систем, поскольку они могут легко представлять отношения между пользователями и предметами, а также атрибуты этих сущностей. Кроме того, использование SQL и языка запросов Cypher облегчает работу с большими массивами данных и выполнение сложных запросов. В целом, мы надеемся, что эта статья послужит отправной точкой для тех, кто заинтересован в создании рекомендательной системы с использованием базы данных графов.