
Содержание
Вы все правильно поняли - вы можете заниматься веб-скреппингом, не покидая своего счастливого места: Google Sheets.
В Google Sheets есть пять встроенных функций, которые помогут вам импортировать данные из других листов и других веб-страниц. Мы рассмотрим их все в порядке от самых простых (наиболее ограниченных) до самых сложных (наиболее мощных).
Вот они, и вы можете нажать на каждую функцию, чтобы перейти к соответствующему разделу. Я также записал видео, в котором рассказываю обо всем:
Вот лист Google, который мы будем использовать для демонстрации каждой функции.
Если вы хотите отредактировать его, создайте копию, выбрав Файл - Создать копию при его открытии.

скриншот листа Google
Как использовать функцию IMPORTRANGE
Это единственная функция, которая импортирует диапазон из другого листа, а не данные с другой веб-страницы. Поэтому, если у вас есть еще один лист Google, вы можете связать эти два листа вместе и импортировать нужные данные из одного листа в другой.
Например, вот лист с кучей случайных данных о Samsung Galaxy.
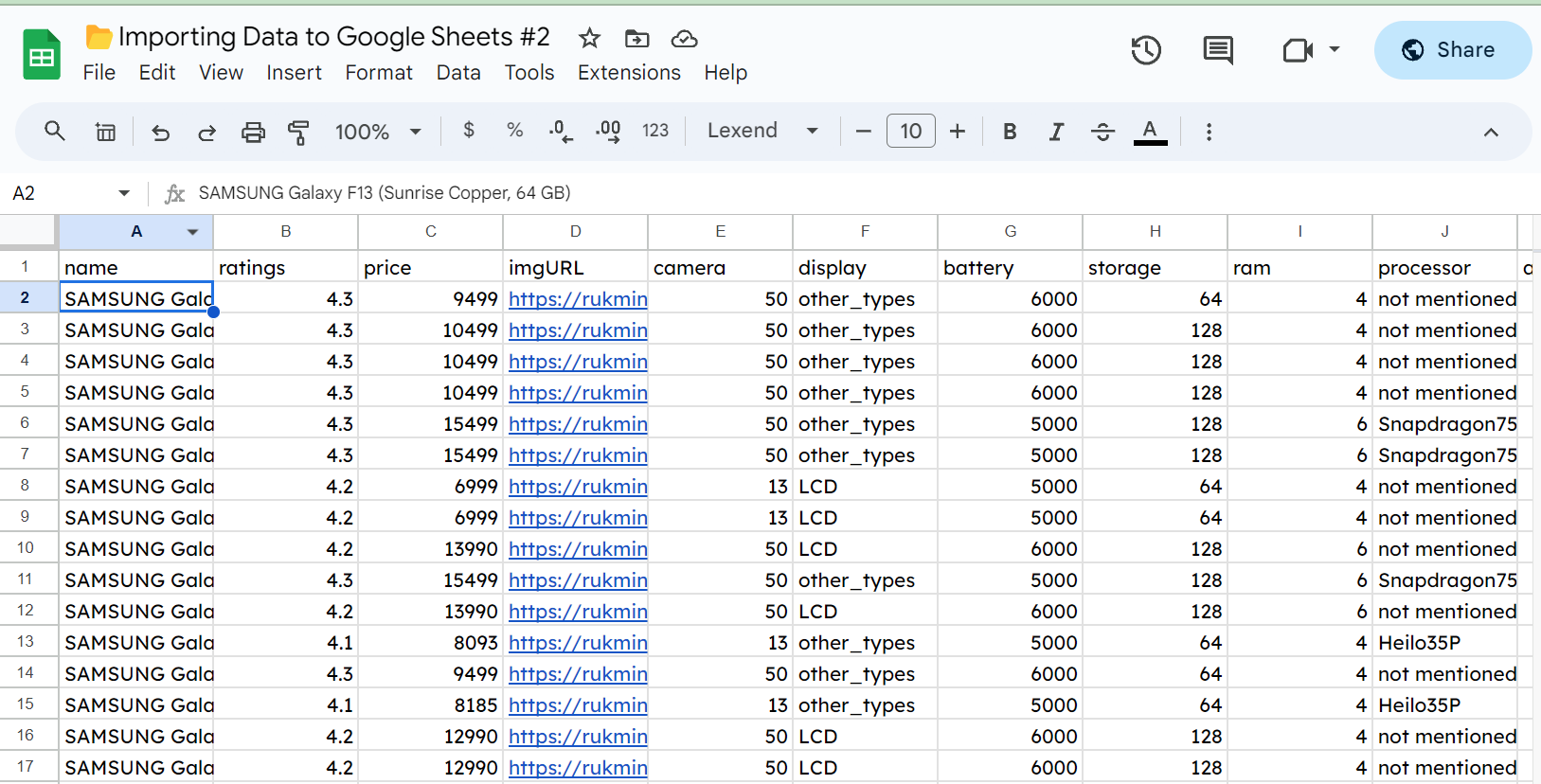
Вы видите, что у нас есть несколько сотен строк данных о телефонах. Если мы хотим импортировать эти данные в другую электронную таблицу, мы можем использовать IMPORTRANGE(). Это самая простая в использовании из пяти функций, которые мы рассмотрим. Все, что ей нужно, - это URL-адрес листа Google и диапазон, который мы хотим импортировать.
Посмотрите на вкладку IMPORTRANGE в листе Google [здесь] (https://docs.google.com/spreadsheets/d/1n8CYEHYktePXJzt5quCBn2gwHvnvTH49vvJziXLnQSE/edit#gid=0), и вы увидите, что в ячейке A5 у нас есть функция =IMPORTRANGE(B4, "data!a1:K"). Она втягивает диапазон A1:K из вкладки data нашей второй электронной таблицы, URL которой находится в ячейке B4.
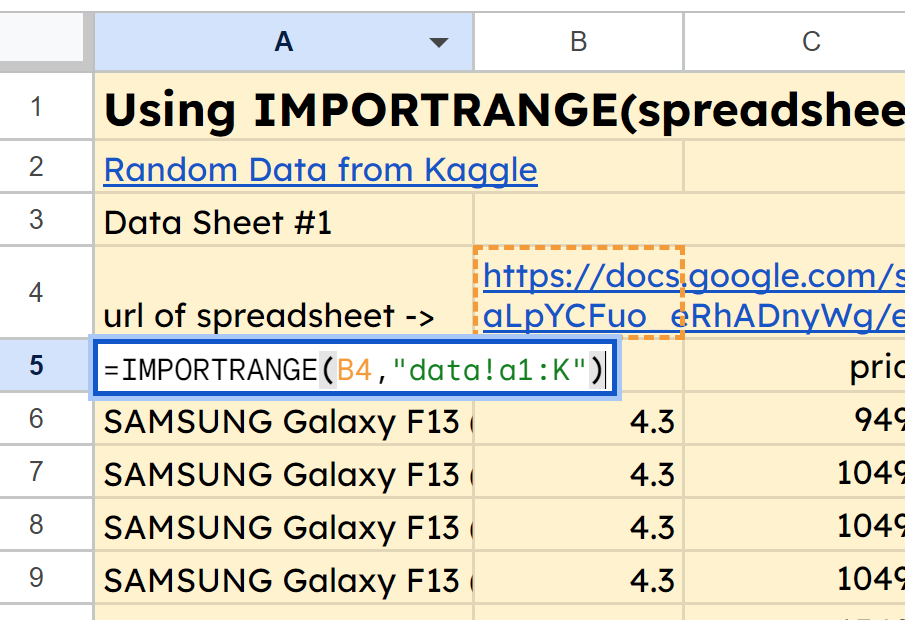
снимок экрана функции IMPORTRANGE
После того как данные попали в вашу электронную таблицу, вы можете сделать одно из двух.
- Оставить их связанными с помощью функции
ИМПОРТРАНЖ. Таким образом, если ваш источник данных будет обновлен, вы получите обновленные данные. - Скопируйте и нажмите CTRL+SHIFT+V, чтобы вставить только значения. Таким образом, у вас будут исходные данные в новой электронной таблице, и вам не придется зависеть от того, изменится ли что-то в URL-адресе в будущем.
Как использовать функцию IMPORTDATA
Это довольно просто. Она импортирует данные в формате .csv или .tsv из любого места в Интернете. Это означает ”значения, разделенные запятыми” и “значения, разделенные табуляцией”.
.csv - наиболее часто используемый тип файлов для финансовых данных, которые необходимо импортировать в электронные таблицы и другие программы.
Как и в случае с IMPORTRANGE, для IMPORTDATA нам нужна всего пара данных: URL, по которому находится файл, и разделитель. Есть также необязательная переменная для локали, но я счел ее излишней.
На самом деле, Google Sheets довольно умны - вы можете не указывать разделитель, и они сами расшифруют, какой тип данных (.csv или .tsv) находится в URL.
Вы можете видеть, что я нашел сайт правительственных данных Нью-Йорка, где хранятся данные о выигрышных номерах лотерей. Я поместил URL-адрес файла .csv в A5, а затем использовал функцию =IMPORTDATA(A5,",") для извлечения данных из файла .csv.

Снимок экрана функции IMPORTDATA
Вы можете загрузить файл .csv, а затем выбрать Файл - Импорт, чтобы добавить эти данные. Но если у вас нет прав на скачивание или вы просто хотите получить данные прямо с сайта, функция IMPORTDATA отлично подойдет.
Как использовать функцию IMPORTFEED
Эта функция импортирует данные из RSS-каналов. Если вы знакомы с подкастингом, вам может быть знаком этот термин. У каждого подкаста есть RSS-канал, который представляет собой структурированный файл, полный XML-данных.
Используя URL-адрес RSS-канала, IMPORTFEED получает данные о подкасте, новостной статье или блоге из его RSS-информации.
Это первая функция, которая начинает иметь в своем распоряжении несколько дополнительных возможностей.
Все, что требуется, - это URL-адрес фида, и он будет получать данные из этого фида. Однако при желании мы можем указать несколько других параметров. Параметры включают:
- [query]: здесь указывается, какие данные брать из фида. Мы можем выбирать из таких опций, как “feed
”, где тип может быть заголовком, описанием, автором или URL. То же самое с “items ”, где типом может быть заголовок, краткое описание, URL или created. - [headers]: это либо приведет заголовки (TRUE), либо нет (FALSE).
- [num_items]: здесь указывается, сколько элементов возвращать при использовании Query. (В документации говорится, что если это значение не указано, то будут возвращены все опубликованные на данный момент элементы, но я не обнаружил, что это так. Мне пришлось указать большее число, чтобы вернуть больше дюжины или около того).
На скриншотах ниже видно, что я запрашиваю одну из моих лент, чтобы получить названия эпизодов и URL-адреса.
Сначала, чтобы получить все названия, я использовал IMPORTFEED(A3, "название элементов", TRUE, 50:
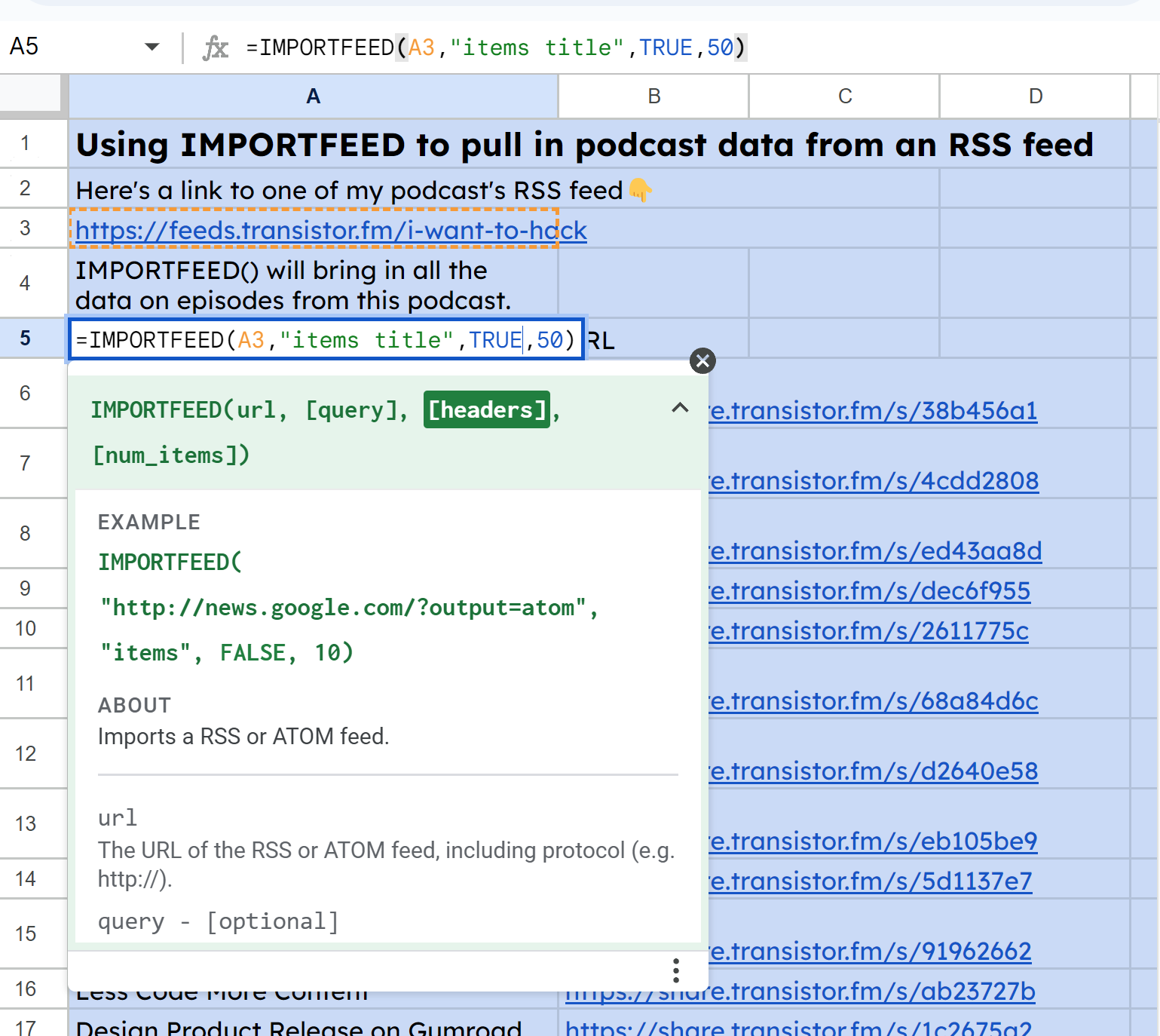
Скриншот IMPORTFEED
Затем, аналогично для URL, я использовал IMPORTFEED(A3, "items url", TRUE, 50):
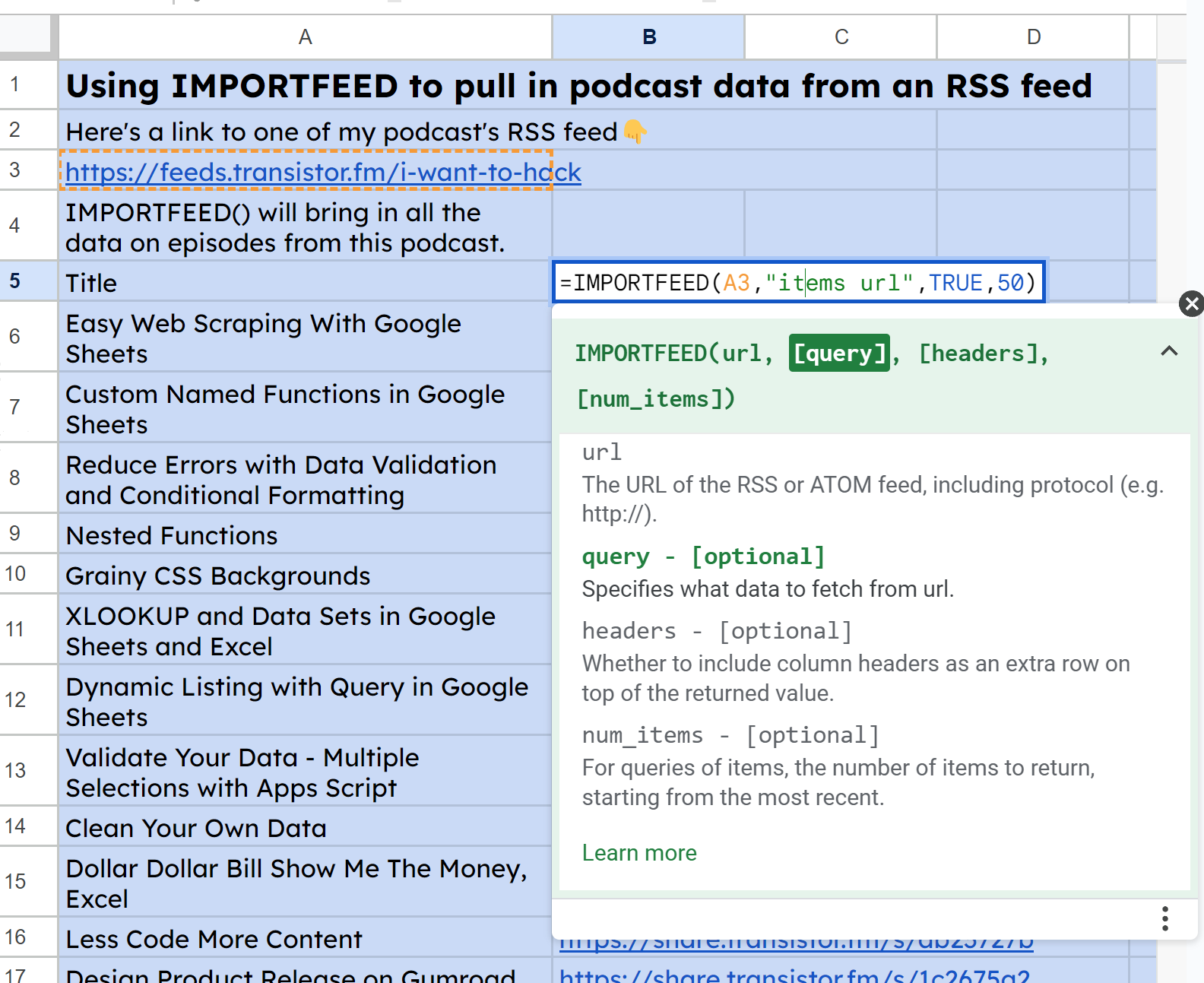
Скриншот IMPORTFEED #2
Как использовать функцию IMPORTHTML
Теперь мы переходим к извлечению данных прямо с веб-сайта. Для этого потребуется URL-адрес, а затем параметр запроса, в котором мы указываем, что нужно искать либо ”таблицу”, либо “список”.
Затем следует значение индекса, указывающее, какую таблицу или список искать, если их несколько на странице. Индекс нулевой, поэтому введите ноль, если вы ищете первую таблицу.
IMPORTHTML просматривает HTML-код сайта в поисках HTML-элементов <table> и <list>.
<!-- Вот как выглядит простая таблица:-->
<table>
<thead>
<tr>
<th>заголовок таблицы 1</th>
<th>заголовок таблицы 2</th>
</tr>
</thead>
<tbody>
<tr>
<td>table data row 1 cell1</td>
<td>строка данных таблицы 1 ячейка2</td>
</tr>
<tr>
<td>строка данных таблицы 2 cell1</td>
<td>строка данных таблицы 2 cell2</td>
</tr>
</tbody>
</table>
<!-- Вот как выглядит упорядоченный список:-->
<ol>
<li>упорядоченный элемент 1</li>
<li>упорядоченный элемент 2</li>
<li>упорядоченный элемент 2</li>
</ol>
<!-- Вот как выглядит неупорядоченный список:-->
<ul>
<li>неупорядоченный элемент 1</li>
<li>неупорядоченный элемент 2</li>
<li>неупорядоченный элемент 3</li>
</ul>
Пример оформления HTML
иВ примере листа в ячейке B3 я разместил URL-адрес некоторых статистических данных о марафонах Баркли, а затем сослался на него в функции A4: =IMPORTHTML(B3, "table",0).
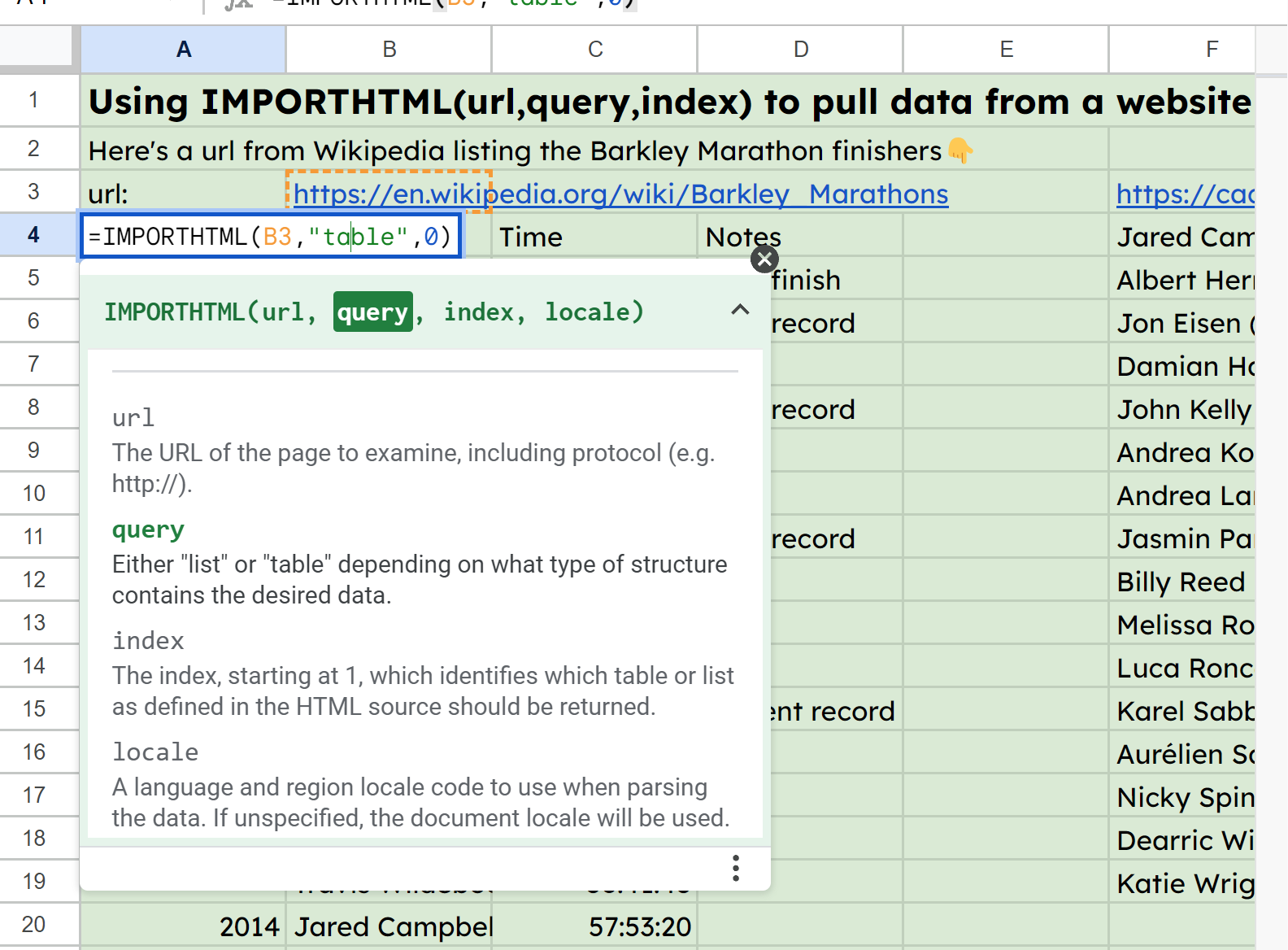
Скриншот IMPORTHTML
К вашему сведению, freeCodeCamp создал ScrapePark как место для практики веб-скрейпинга, так что вы можете использовать его для IMPORTHTML и IMPORTXML, о которых речь пойдет дальше👇.
Как использовать функцию IMPORTXML
Мы приберегли самое лучшее напоследок. Эта функция будет просматривать веб-сайты и соскребать практически все, что мы захотим. Правда, это сложно, потому что вместо импорта всех данных таблицы или списка, как в IMPORTHTML, мы пишем запросы, используя так называемый XPath.
XPath - это язык выражений, который используется для запросов к XML-документам. Мы можем написать выражения XPath, чтобы заставить IMPORTXML импортировать всевозможные данные с HTML-страницы.
Существует множество ресурсов для поиска подходящих выражений XPath. Вот один из них, который я использовал для этого проекта.
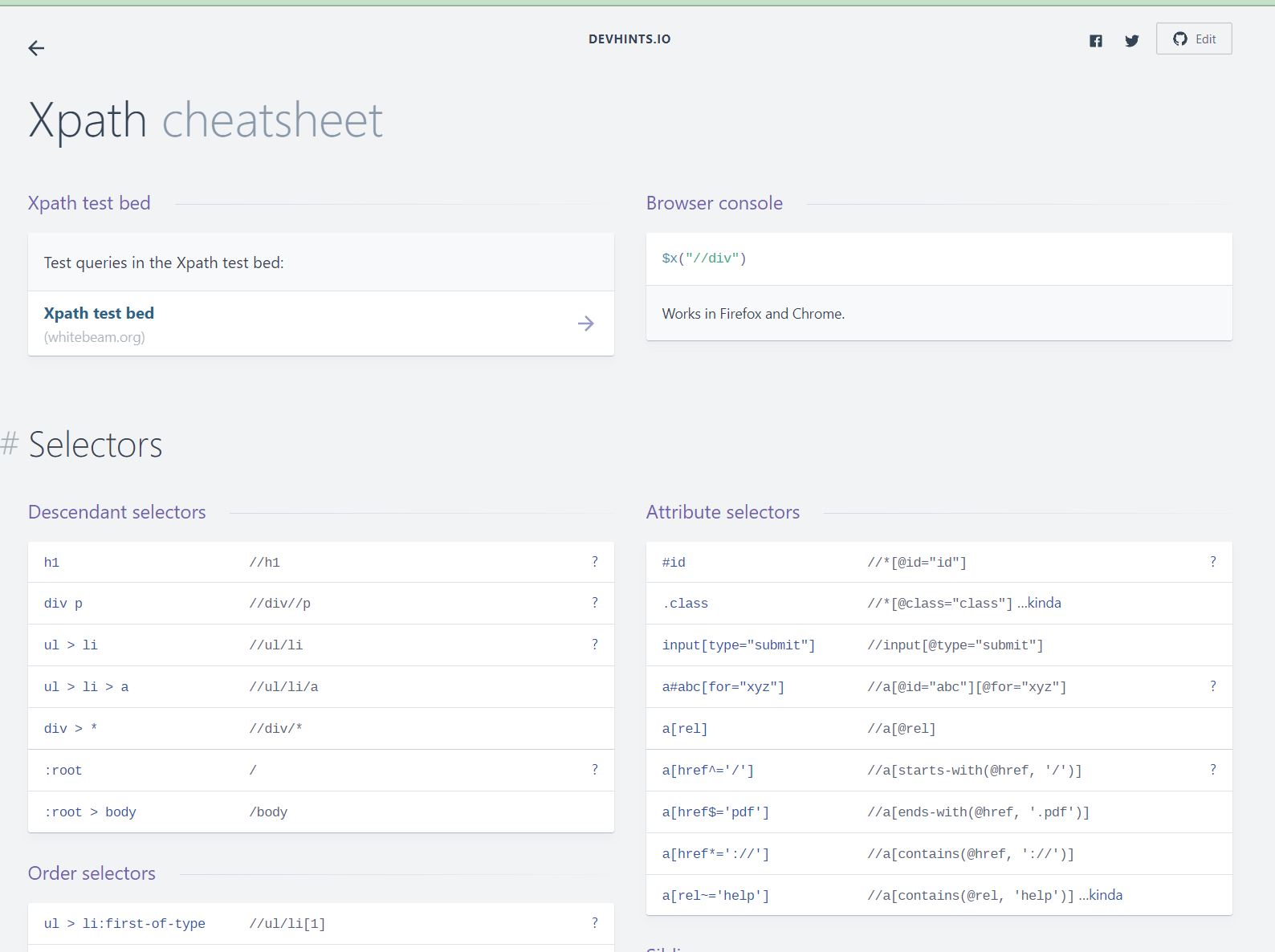
скриншот шпаргалки по XPath
В листе для IMPORTHTML я привел несколько примеров, которые рекомендую вам просмотреть и проверить.
Например, использование функции =IMPORTXML(A11,"//*[@class='post-card-title']") позволяет нам привести все заголовки моих статей, потому что, изучив HTML на моей авторской странице здесь, я обнаружил, что все они имеют класс post-card-title.
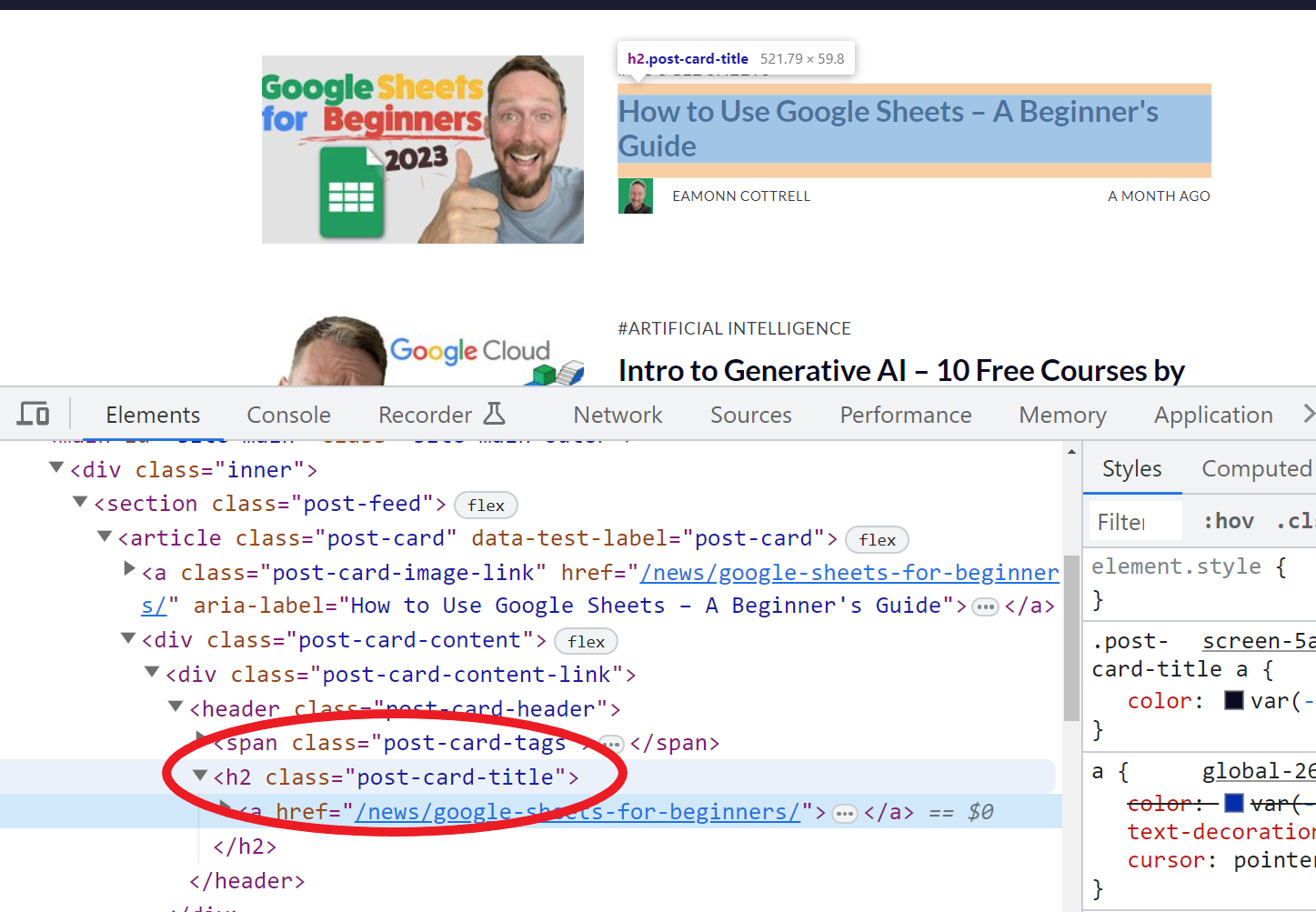
скриншот осмотра веб-страницы с помощью dev tools
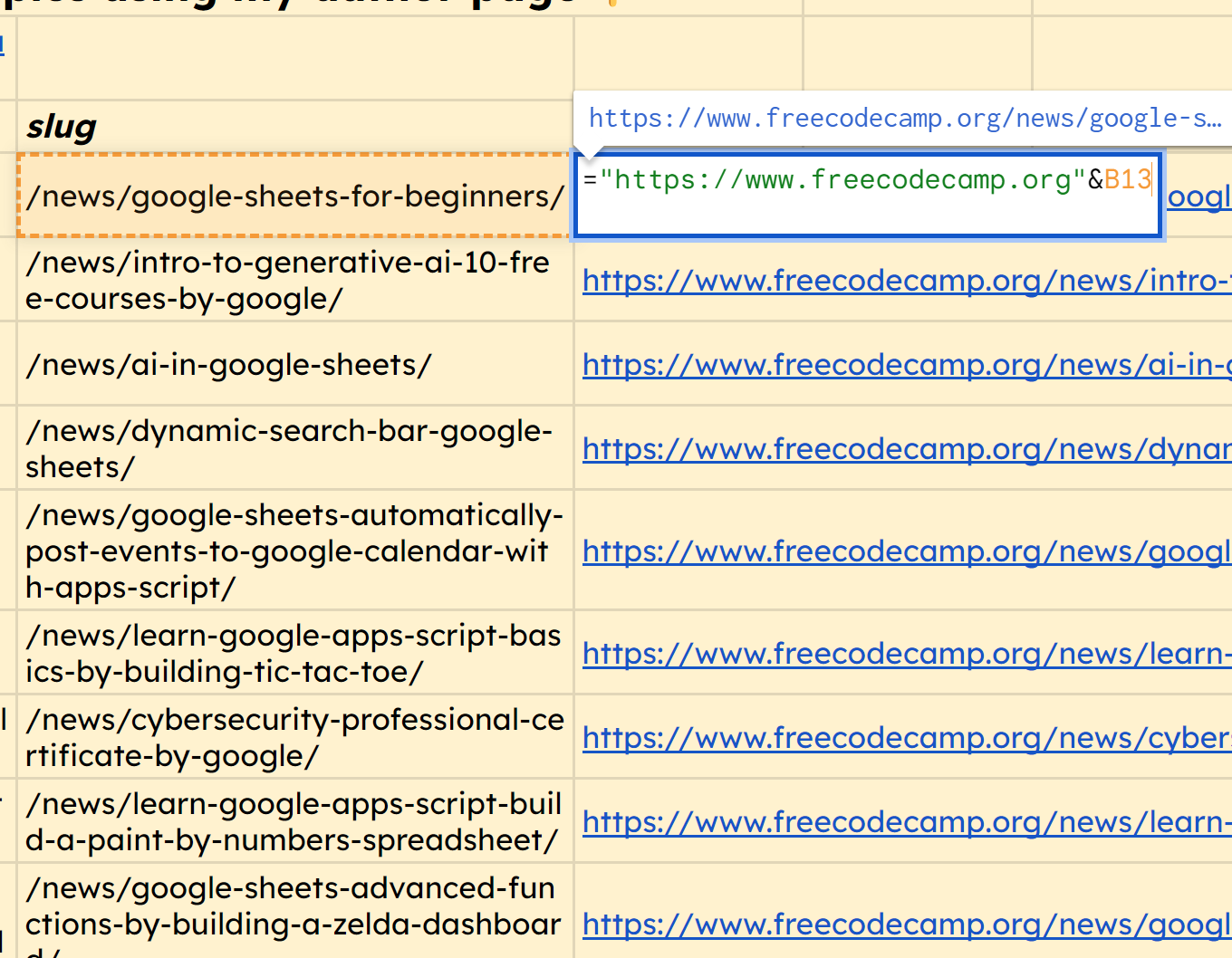
Таким же образом мы можем использовать функцию =IMPORTXML(A11,"//*[@class='post-card-title']//a/@href"), чтобы получить URL-слог каждой из этих статей.
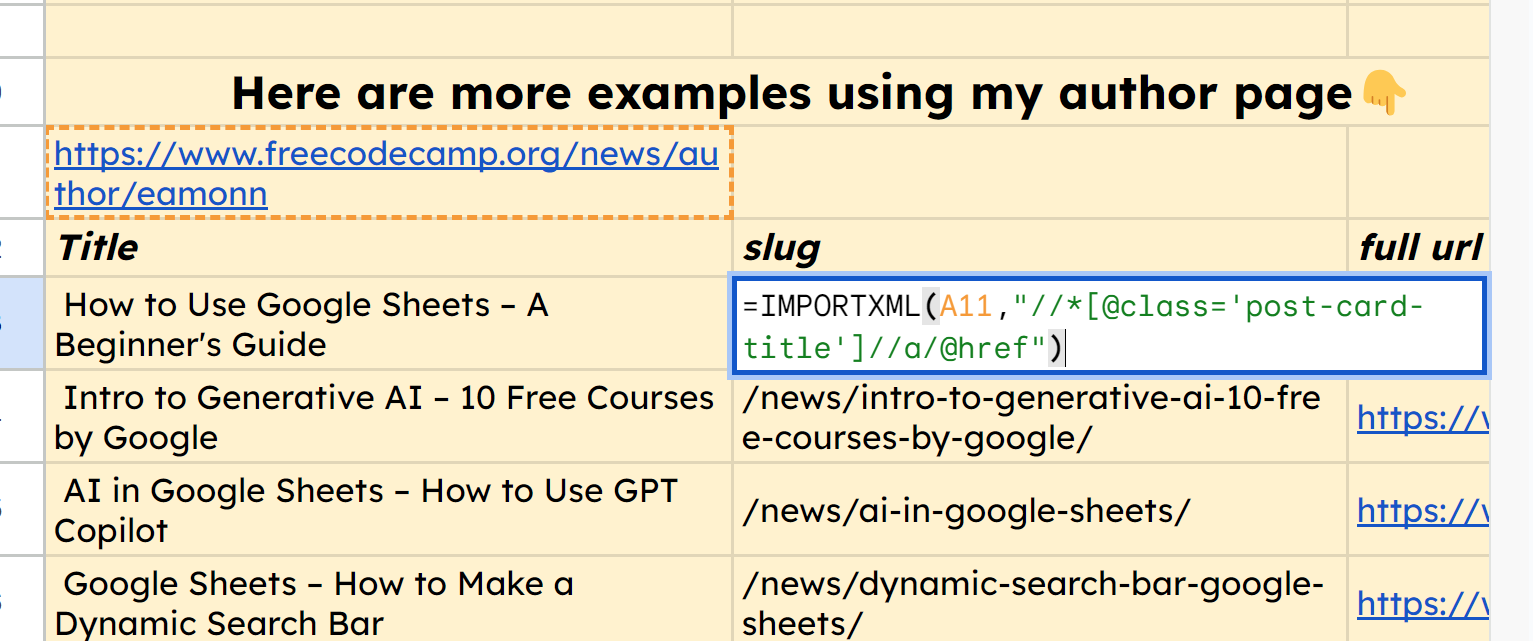
скриншот IMPORTXML
Вы заметите, что он выводит полный URL, поэтому в качестве бонуса мы можем просто добавить домен к каждому из них. Вот функция для первой строки, которую мы можем перетащить вниз, чтобы получить все эти правильные URL: ="https://www.freecodecamp.org"&B13.
скриншот добавления домена к slug