
Содержание
OpenAI’s GPT стал передовым инструментом искусственного интеллекта во всем мире и умеет отвечать на запросы, основанные на обучающих данных. Однако он не может ответить на вопросы о неизвестных темах, таких как недавние события после сентября 2021 года, ваши непубличные документы или информация из прошлых разговоров. Эта задача становится еще сложнее, когда вы имеете дело с данными реального времени, которые часто меняются. Кроме того, вы не можете предоставлять GPT обширный контент, и он не может хранить ваши данные в течение длительного времени.
В этом случае вам необходимо создать собственное приложение LLM (Language Learning Model), которое будет эффективно передавать контекст в процессе ответа. Многообещающий подход, который можно найти в Интернете, - это использование LLM с векторными базами данных, что связано с такими расходами, как увеличение объема подготовительной работы, инфраструктуры и сложности. Поддерживать синхронизацию исходных текстов и векторов очень сложно. Вместо этого вы можете использовать библиотеку с открытым исходным кодом LLM App на Python для реализации индексации данных в реальном времени в памяти, напрямую считывая данные из любого совместимого хранилища и отображая их в пользовательском интерфейсе Streamlit.
В этом материале вы узнаете, как разработать трекеры сделок в реальном времени с использованием этих инструментов. Исходный код находится на GitHub.
Цели обучения
В ходе статьи вы узнаете следующее:
- Причины, по которым вам необходимо добавлять пользовательские данные в ChatGPT.
- Как использовать вкрапления, инженерию подсказок и ChatGPT для улучшения качества ответов на вопросы.
- Создайте свой собственный ChatGPT с пользовательскими данными с помощью приложения LLM.
- Создайте Python API ChatGPT для поиска цен со скидками в реальном времени.
Образец задачи приложения
Вдохновленное этой статьей о корпоративном поиске, наше приложение должно представлять конечную точку HTTP REST API на Python для ответа на запросы пользователей о текущих распродажах путем получения последних предложений из различных источников (CSV, Jsonlines, API, брокеров сообщений или баз данных), фильтровать и представлять предложения на основе запросов пользователя или выбранных источников данных, использовать конечные точки OpenAI API Embeddings и Chat Completion для генерации ответов AI-ассистента и предлагать удобный пользовательский интерфейс с Streamlit.
В настоящее время проект поддерживает два типа источников данных и возможность расширения источников путем добавления пользовательских входных коннекторов:
- Jsonlines - источник данных ожидает наличия объекта
docдля каждой строки. Убедитесь, что вы сначала преобразовали ваши входные данные в Jsonlines. Смотрите пример данных в discounts.jsonl - Rainforest Product API - предоставляет нам все доступные данные о ежедневных скидках из товаров Amazon.
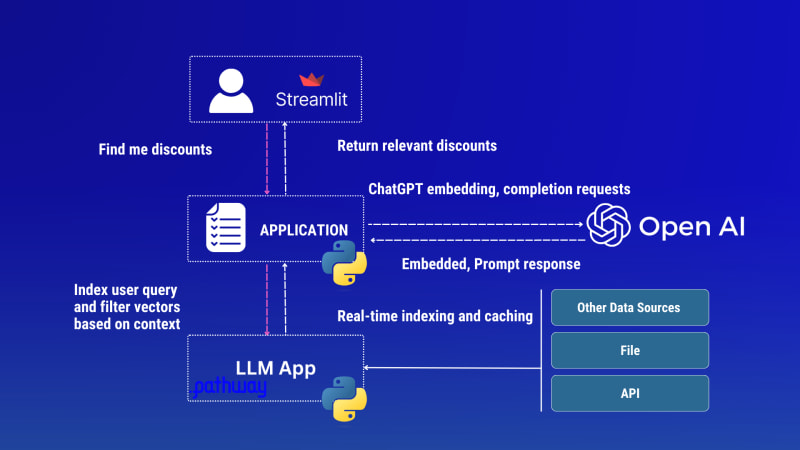
Архитектурная схема приложения Discounts tracker LLM App
После того как мы передадим эти знания GPT с помощью Streamlit UI (применив источник данных), посмотрите, что он ответит:

Приложение учитывает как Rainforest API, так и документы файла discounts.csv (мгновенно объединяет данные из этих источников), индексирует их в режиме реального времени и использует эти данные при обработке запросов.
Зачем предоставлять ChatGPT пользовательскую базу знаний?
Прежде чем перейти к рассмотрению способов расширения ChatGPT, давайте сначала изучим ручные методы и определим их проблемы. Как правило, ChatGPT расширяется с помощью программного инжиниринга. Предположим, что вам нужно найти дисконнекты в реальном времени.ts/deals/coupons из различных онлайн-маркетов.
Например, когда вы спрашиваете ChatGPT ”Можете ли вы найти мне скидки на этой неделе на мужскую обувь Adidas?”, стандартный ответ, который вы можете получить из интерфейса ChatGPT UI, не имея специальных знаний, таков:

Как видно, GPT предлагает общие рекомендации по поиску скидок, но не хватает конкретики относительно того, где и какие скидки, а также других деталей. Теперь, чтобы помочь модели, мы дополняем ее информацией о скидках из надежного источника данных. Вы должны взаимодействовать с ChatGPT, добавив начальный контент документа перед размещением фактических вопросов. Мы соберем пример данных из набора данных Amazon products deal и вставим в запрос только один имеющийся у нас элемент JSON:

Как видите, вы получаете ожидаемый результат, и это довольно просто сделать, поскольку ChatGPT теперь ориентирован на контекст. Однако проблема этого метода заключается в том, что контекст модели ограничен (gpt-4 максимальная длина текста составляет 8 192 токена). Эта стратегия быстро станет проблематичной, когда входные данные будут огромными, вы можете ожидать тысячи обнаруженных предметов в продажах, и вы не сможете предоставить этот большой объем данных в качестве входного сообщения. Кроме того, после сбора данных вы можете захотеть очистить, отформатировать и предварительно обработать данные, чтобы обеспечить их качество и релевантность. Если вы используете конечную точку OpenAI [Chat Completion endpoint] (https://platform.openai.com/docs/api-reference/chat) или создаете [пользовательские плагины для ChatGPT] (https://openai.com/blog/chatgpt-plugins), это создает другие проблемы, перечисленные ниже:
- Стоимость - Предоставление более подробной информации и примеров может повысить производительность модели, хотя и с большими затратами (для GPT-4 с входом в 10 тыс. токенов и выходом в 200 токенов стоимость одного предсказания составляет $0,624). Многократная отправка одинаковых запросов может привести к увеличению затрат, если не использовать локальную систему кэширования.
- Задержка - Проблема использования API ChatGPT для производства, как и API OpenAI, заключается в их непредсказуемости. Нет никаких гарантий относительно предоставления стабильного сервиса.
- Безопасность - При интеграции пользовательских плагинов каждая конечная точка API должна быть указана в OpenAPI spec для обеспечения функциональности. Это означает, что вы раскрываете ChatGPT свои внутренние настройки API, к чему многие предприятия относятся скептически.
- Оффлайн-оценка - Проведение офлайн-тестов кода и данных или локальная репликация потока данных - сложная задача для разработчиков. Это связано с тем, что каждый запрос к системе может давать разные ответы.
Tutorial
Вы можете выполнить следующие шаги, чтобы понять, как создать приложение поиск скидок. Исходный код проекта можно найти на GitHub. Если вы хотите быстро начать использовать приложение, вы можете пропустить эту часть, клонировать репозиторий и запустить пример кода, следуя инструкциям в файле README.md. Учебник состоит из двух частей:
- Разработка и экспонирование HTTP REST API с поддержкой ИИ с помощью Pathway и LLM App.
- Разработка пользовательского интерфейса с помощью Streamlit для использования данных API через REST.
Часть 1: Разработка API
Чтобы добавить пользовательские данные для ChatGPT, сначала нужно выполнить шаги по созданию конвейера данных для получения, обработки и представления данных в режиме реального времени с помощью приложения LLM.
Шаг 1. Сбор данных (ввод пользовательских данных).
Для простоты мы можем использовать любой Jsonlines в качестве источника данных. Приложение принимает файлы Jsonlines типа discounts.jsonl и мыиспользует эти данные при обработке пользовательских запросов. Источник данных ожидает, что для каждой строки будет создан объект doc. Убедитесь, что вы сначала преобразовали входные данные в Jsonlines. Вот пример Jsonline-файла с одной необработанной строкой:
{
"doc": "{'position': 1, 'link': 'https://www.amazon.com/deal/6123cc9f', 'asin': 'B00QVKOT0U', 'is_lightning_deal': False, 'deal_type': 'DEAL_OF_THE_DAY', 'is_prime_exclusive': False, 'starts_at': '2023-08-15T00:00:01.665Z', 'ends_at': '2023-08-17T14:55:01.665Z', 'type': 'multi_item', 'title': 'Deal on Crocs, DUNLOP REFINED(\u30c0\u30f3\u30ed\u30c3\u30d7\u30ea\u30d5\u30a1\u30a4\u30f3\u30c9)', 'image': 'https://m.media-amazon.com/images/I/41yFkNSlMcL.jpg', 'deal_price_lower': {'value': 35.48, 'currency': 'USD', 'symbol': '$', 'raw': '35.48'}, 'deal_price_upper': {'value': 52.14, 'currency': 'USD', 'symbol': '$', 'raw': '52.14'}, 'deal_price': 35.48, 'list_price_lower': {'value': 49.99, 'currency': 'USD', 'symbol': '$', 'raw': '49.99'}, 'list_price_upper': {'value': 59.99, 'currency': 'USD', 'symbol': '$', 'raw': '59.99'}, 'list_price': {'value': 49.99, 'currency': 'USD', 'symbol': '$', 'raw': '49.99 - 59.99', 'name': 'List Price'}, 'current_price_lower': {'value': 35.48, 'currency': 'USD', 'symbol': '$', 'raw': '35.48'}, 'current_price_upper': {'value': 52.14, 'currency': 'USD', 'symbol': '$', 'raw': '52.14'}, 'current_price': {'value': 35.48, 'currency': 'USD', 'symbol': '$', 'raw': '35.48 - 52.14', 'name': 'Current Price'}, 'merchant_name': 'Amazon Japan', 'free_shipping': False, 'is_prime': False, 'is_map': False, 'deal_id': '6123cc9f', 'seller_id': 'A3GZEOQINOCL0Y', 'description': 'Deal on Crocs, DUNLOP REFINED(\u30c0\u30f3\u30ed\u30c3\u30d7\u30ea\u30d5\u30a1\u30a4\u30f3\u30c9)', 'rating': 4.72, 'ratings_total': 6766, 'page': 1, 'old_price': 49.99, 'currency': 'USD'}"
}
Самое интересное, что приложение всегда в курсе изменений в папке data. Если вы добавляете еще один файл JSONlines, приложение LLM делает волшебство и автоматически обновляет ответ модели AI.
Шаг 2: Загрузка и сопоставление данных
С помощью входного коннектора JSONlines Pathway мы прочитаем локальный файл JSONlines, отобразим записи данных в схему и создадим таблицу Pathway. Полный исходный код см. в app.py:
sales_data = pw.io.jsonlines.read(
"./examples/data",
schema=DataInputSchema,
mode="streaming"
)
Сопоставление каждой строки данных со структурированной схемой документа. Полный исходный код см. в app.py:
class DataInputSchema(pw.Schema):
doc: str
Шаг 3: Встраивание данных
Каждый документ embedded с помощью OpenAI API и извлекает встроенный результат. Полный исходный код см. в embedder.py:
embedded_data = embeddings(context=sales_data, data_to_embed=sales_data.doc)
Шаг 4: Индексирование данных
Затем мы строим мгновенный индекс по сгенерированным вкраплениям:
index = index_embeddings(embedded_data)
Шаг 5: Обработка пользовательских запросов и индексирование
Мы создаем конечную точку REST, берем пользовательский запрос из полезной нагрузки запроса API и встраиваем его в API OpenAI.
query, response_writer = pw.io.http.rest_connector(
host=host,
port=port,
schema=QueryInputSchema,
autocommit_duration_ms=50,
)
embedded_query = embeddings(context=query, data_to_embed=pw.this.query)
Шаг 6: Поиск сходства и проектирование подсказок
Мы выполняем поиск по сходству, используя индекс для определения наиболее релевантных совпадений для вставки запроса. Затем мы создаем подсказку, которая объединяет запрос пользователя с найденными релевантными результатами данных и отправляет сообщение в конечную точку завершения ChatGPT для получения правильного и подробного ответа.
responses = prompt(index, embedded_query, pw.this.query)
Мы использовали тот же подход к контекстному обучению, когда разрабатывали подсказки и добавляли внутренние знания в ChatGPT в prompt.py.
prompt = f "Учитывая следующие данные о скидках: \\\n {docs_str} \\\nответьте на этот запрос: {query}"
Шаг 7: Return the response
Последним шагом будет возвращение ответа API пользователю
# Построение запроса с использованием индексированных данных
responses = prompt(index, embedded_query, pw.this.query)
Шаг 9: Соберите все вместе
Теперь, если мы соберем все вышеописанные шаги вместе, у вас будет готовый к использованию Python API с поддержкой LLM для пользовательских данных о скидках, как вы видите реализацию в Python-скрипте app.py.
import pathway as pw
from common.embedder import embeddings, index_embeddings
from common.prompt import prompt
def run(host, port):
# Получаем вопрос пользователя в виде запроса из вашего API
query, response_writer = pw.io.http.rest_connector(
host=host,
port=port,
schema=QueryInputSchema,
autocommit_duration_ms=50,
)
# Данные в реальном времени, поступающие из внешних источников данных, таких как файл jsonlines
sales_data = pw.io.jsonlines.read(
"./examples/data",
schema=DataInputSchema,
mode="streaming"
)
# Вычисление вкраплений для каждого документа с помощью OpenAI Embeddings API
embedded_data = embeddings(context=sales_data, data_to_embed=sales_data.doc)
# Построение индекса по сгенерированным эмбеддингам в режиме реального времени
index = index_embeddings(embedded_data)
# Генерируем эмбеддинги для запроса из OpenAI Embeddings API
embedded_query = embeddings(context=query, data_to_embed=pw.this.query)
# Постройте подсказку, используя проиндексированные данные
responses = prompt(index, embedded_query, pw.this.query)
# Отправьте запрос в ChatGPT и получите сгенерированный ответ.
response_writer(responses)
# Запуск конвейера
pw.run()
class DataInputSchema(pw.Schema):
doc: str
class QueryInputSchema(pw.Schema):
query: str
Часть 2: Добавляем интерактивный пользовательский интерфейс
Чтобы сделать ваше приложение более интерактивным и удобным, вы можете использовать Streamlit для создания внешнего приложения. Посмотрите реализацию в этом файле app.py. Как видно из приведенного ниже извлеченного кода реализации Streamlit, он обрабатывает запросы API Discounts (мы раскрывали их в части 1), если выбран источник данных и задан вопрос:
if data_sources and question:
``если не os.path.exists(csv_path) и не os.path.exists(rainforest_path):
st.error("Не удалось обработать файл скидок")
url = f'http://{api_host}:{api_port}/'
data = {"query": question}
response = requests.post(url, json=data)
if response.status_code == 200:
st.write("### Ответ")
st.write(response.json())
else:
st.error(f "Не удалось отправить данные в Discounts API. Код состояния: {response.status_code}")
Запуск приложения
Для запуска приложения следуйте инструкциям в разделе Как запустить проект файла README.md. Обратите внимание, что вам нужно запустить API и UI отдельно как два разных процесса. Streamlit автоматически подключается к API бэкенда Discounts, и вы увидите, что фронтенд UI запущен в вашем браузере.

Потоковый пользовательский интерфейс для трекера скидок.
Технически, есть и другие способы интеграции приложения Pathway’s LLM App со Streamlit:
- Вы можете запустить приложение Pathway’s LLM App как подпроцесс, взаимодействующий с подпроцессом через межпроцессные коммуникации (сокеты или TCP/IP, возможно, с произвольными портами, возможно, с сигналами, например, для запуска дампа состояния, который может быть взят/пикирован).
- Также можно запустить приложение с помощью одной команды
docker compose up. См. раздел Запуск с помощью Docker в файле README.md.
Подведение итогов
Мы открыли лишь некоторые возможности LLM App, добавив в ChatGPT специфические для данной области знания, например, о скидках. Вы можете добиться гораздо большего:
- Включайте дополнительные данные из внешних API, а также различные файлы (например, Jsonlines, PDF, Doc, HTML или текстовый формат), базы данных, такие как PostgreSQL или MySQL, и потоковые данные с таких платформ, как Kafka, Redpanda или Debedizum.
- Улучшите пользовательский интерфейс Streamlit, чтобы он мог принимать любой API сделок, кроме Rainforest API.
- Сохраняйте снимки данных, чтобы наблюдать за изменениями цен продаж с течением времени, поскольку Pathway предоставляет встроенную функцию для вычисления разницы между двумя изменениями.
- Помимо предоставления доступа к данным через API, приложение LLM App позволяет передавать обработанные данные другим коннекторам, таким как BI и аналитические инструменты. Например, настройте его на получение оповещений при обнаружении ценовых сдвигов.
Если у вас есть вопросы, задавайте их в комментариях ниже или свяжитесь со мной на LinkedIn и Twitter. Присоединяйтесь к каналу Discord, чтобы посмотреть, как работает AI ChatBot помощник с помощью приложения LLM.
Об авторе
Посетите мой блог: www.iambobur.com